| 本小节对NEON做简单介绍 NEON 技术可加速多媒体和信号处理算法(如视频编码/解码、2D/3D 图形、游戏、音频和语音处理、图像处理技术、电话和声音合成),其性能至少为 ARMv5 性能的 3 倍,为 ARMv6 SIMD 性能的 2 倍。 通过干净方式构建的 NEON 技术可无缝用于其本身的独立管道和寄存器文件。 NEON 技术是 ARM Cortex™-A 系列处理器的 128 位 SIMD(单指令,多数据)架构扩展,旨在为消费性多媒体应用程序提供灵活、强大的加速功能,从而显著改善用户体验。它具有 32 个寄存器,64 位宽(双倍视图为 16 个寄存器,128 位宽。) NEON 指令可执行“打包的 SIMD”处理:
使用 NEON 技术的 ARM Cortex™-A 系列处理器,以及 ARM 的 Mali 多媒体硬件解决方案可用于多媒体应用,范围从智能手机和移动计算设备到 HDTV。 NEON是ARM公司的商标,也是高端ARM处理器集成的硬IP,类似intel的MMX、SSE硬件指令集。 NEON 的特征和优点NEON 支持用于 Internet 应用程序的范围广泛的多媒体编解码器:
如何使用 NEONOpenMAX DL 库:
开源社区中的 NEON 支持 当前,在以下开源项目中支持 NEON:
DSP 扩展 ARM DSP 指令集扩展增加了高性能应用中 ARM 解决方案的 DSP 处理能力,同时通过便携式、电池电源设备提供所需的低能耗。DSP 扩展已经过优化,适用于众多软件应用(包括伺服马达控制、Voice over IP (VOIP) 和视频/音频编解码器),其中此扩展可增强 DSP 性能,使其能够有效处理所需任务。 特点
应用
用于 ARM 架构的编译器可以使用这些 DSP 扩展来改进标准 C 和 C++ 软件的代码生成过程,或者允许软件开发人员要求通过内部函数或内联汇编代码显式使用这些扩展。 ARM DSP 扩展改进了 DSP 性能,且无需非常高的时钟频率。几乎不增加典型实现中的功耗即可获得此性能。DSP 扩展广泛应用于智能手机以及需要大量信号处理的类似嵌入式系统,从而避免使用其他硬件加速器。DSP 扩展可与 32 位 ARM 和 16 位Thumb® 指令集完全兼容,从而确保所有现有操作系统和应用程序代码都可在支持 DSP 且基于 ARM 处理器的设备上重用。这些扩展广泛适用于大量细分市场,包括无线、大容量存储、汽车、消费娱乐和数字图像。 NEON原理 NEON 指令可执行“打包的 SIMD”处理: 寄存器被视为同一数据类型的元素的矢量 数据类型可以为:签名/未签名的 8 位、16 位、32 位、64 位单精度浮点 原理图如下:  下图通过SISD(单指令单数据)和SIMD(单指令多数据)的对比,来说明NEON的工作原理: 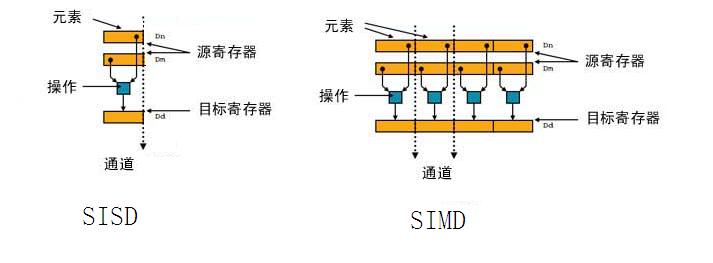 从图上可以看到,对于SISD,每个指令只能处理一个数据,而SIMD一个指令可以处理多个数据,因为多个数据的处理是平行的,因此从时间来说,一个指令执行的时间,SISD和SIMD是差不多的。由于SIMD一次可以处理N个数据,所以它的处理的时间也就缩短到SISD的1/N。 需要指出一点,NEON是需要硬件的支持的,需要有一块寄存器放到硬件上来处理这个的。 NEON的使用 NEON的函数是C语言风格,但是编译后成为汇编语句,这样执行的效率会提高。 NEON代码的计算效率很高,举例1为实现信号增益的代码实例。 举例1 标准C语言: for(i=0;i { output=input; } 上述代码每次迭代仅能处理单一的值,通过这个展开循环可以进一步提高效率。 for(i=0;i { output=input; output[i+1]=input[i+1]; output[i+2]=input[i+2]; output[i+3]=input[i+3]; } 这样可以减少系统资源开销,提高性能,增加并发代码可能性。可是,乘法指令循环复杂的问题仍然存在,使用NEON内部函数,代码看起来会截然不同。 for(i=0;i { //加载 samples_f32=vldlq_f32(input+i); //执行乘法运算 samples_f32=vmulq_f32(samples_f32,1.2); //储存结果 samples_f32=vstlq_f32(output+i,samples_f32); } 举例2 下面是一个用C现实的将GRB转化成灰度图的算法  下面是一个用NEON现实的将GRB转化成灰度图的算法 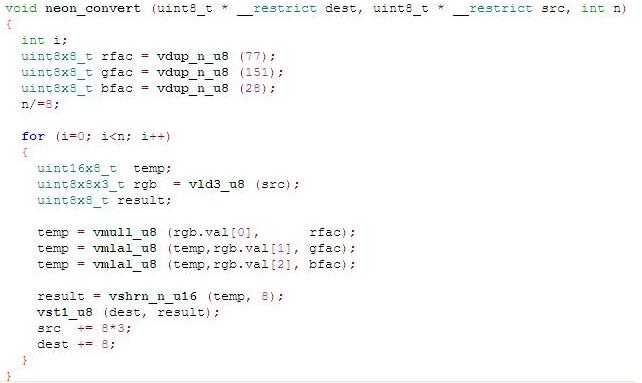 对以上函数进行说明如下: 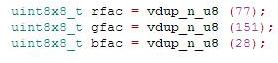 把权重放入NEON寄存器 一次载入8 pixles到三个NOEN寄存器,这个地方是重点可以说明NEON的高效率。 计算结果 |




 其实我看不懂 只是前来围观 学习
其实我看不懂 只是前来围观 学习


 京公网安备 11010802033920号
京公网安备 11010802033920号
