



历史上的今天
今天是:2025年03月18日(星期二)
2019年03月18日 | Facebook 未来机器学习平台
2019-03-18 来源:半导体行业观察翻译自「nextplatform」
粗看上去,世界上的超大规模用户和云构建商制造的东西通常看上去和感觉上去都像超级计算机,但如果你仔细观察,就常会看到一些相当大的差异。差异之一是,他们的机器并不是为了实现最高性能而不惜一切代价去设计,而是在性能和成本之间实现了最佳平衡。
简而言之,这就是为什么社交网络巨头Facebook(世界上最大的人工智能用户之一)大量订购英伟达的HGX-1和HGX-2系统用于机器学习训练,然后就到此为止了。(HGX-1和HGX-2系统是GPU加速器制造商英伟达的DGX系列的超大规模用户版本。)
这并不是巧合,为什么微软、谷歌、亚马逊网络服务、阿里巴巴、腾讯、百度,以及中国第四大巨头(中国移动或京东)同样设计自己的服务器,或是使用Facebook在2011年创建的开放计算项目(OCP)中的设计,或是在OCP启动六个月后由阿里巴巴、百度和腾讯发起了天蝎计划项目。在某些情况下,他们甚至设计自己的ASIC或在FPGA上运行专门用于机器学习的算法。
公平地说,Facebook确实在2017年6月安装了英伟达DGX-1 CPU-GPU混合系统的半定制实现,该系统有124个节点,峰值双精度性能为4.9 petaflops,在HPC常用的Linpack并行Fortran基准测试中的评价为3.31petaflops。但这是个例外,不是常规。
但是,Facebook喜欢设计自己的硬件,然后将其开源,试图围绕这些设计构建一个生态系统,以降低工程和制造成本,并降低供应链风险,因为越来越多的公司进入了开放计算领域。这与微软几年前加入OCP并将一系列完全不同的开源基础设施设计(从服务器到存储到交换)抛入OCP生态系统的原因相同。这增加了创新,但也导致了供应链分叉。
在本周于圣何塞举行的OCP全球峰会上,Facebook展示了针对机器学习训练和基础设施的未来系统设计,让世界有机会看到针对现代数据中心的这两个日益重要的工作负载的成本优化设备的至少一个潜在的未来。这些设计非常有趣,表明Facebook热衷于创建能够容纳尽可能多的供应商的不同类型计算的系统,再次降低成本和供应链风险。
不是基本训练
第一台新机器代号为“Zion”,它的目标是Facebook上的机器学习训练工作负载。Zion系统由两个不同的子系统组成,就像英伟达的DGX-1和微软的HGX-1,也包括DGX-2和HGX-2,以及ODM和OEM厂商为客户制造的各种等价产品。 Zion系统是两年前Facebook在OCP峰会上与微软的HGX-1一起发布的“Big Basin”ceepie-geepie系统的继承者,这两个系统的设计都为OCP做出了贡献。Big Basin机器的主机支持多达8个英伟达的“Pascal”GP100或“Volta”GV100 GPU加速器,以及两个英特尔Xeon CPU。巧妙之处在于CPU计算和GPU计算是分开的,分别位于不同的主板和不同的机箱中,因此它们可以单独升级。具体取决于品牌和型号。
Big Basin是对其前身“Big Sur”的彻底改进,后者是一款密度较低的设计,基于单个主板,配备两个Xeon CPU和多达8个PCI-Express Nvidia Tesla加速器(M40或K80是最受欢迎的)。Big Sur于2015年12月曝光。Facebook在谈到设计时表示,开发工作已经基本完成,还没有投入生产,这意味着Zion机器还没有投入生产,但很快就会问世。(我们在2018年1月讨论了Facebook不断演变的AI工作负载,以及运行这些工作负载的机器。)Zion机器的变化显示了Facebook在混合CPU-GPU机器上的想法的变迁,这些想法是我们许多人都想不到的。
Zion机器的两个子系统被称为“Emerald Pools”和“Angels Landing”,分别指的是GPU和CPU子系统。尽管facebook多年来一直表示,其服务器设计的目的是允许选择处理器或加速器,但在这个例子中,facebook和微软合作提出了一种独特的封装和主板插接方法,称为OCP加速器模块(简称OAM),该方法允许使用具有不同插座和热量的加速器,可以选择250瓦至350瓦不等的风冷,未来则可以选择高达700瓦的水冷,但就硬件形式而言,所有这些都一致部署在这些加速系统中。
超大规模用户谷歌、阿里巴巴和腾讯将与Facebook和微软一起推广OAM封装,芯片制造商AMD、英特尔、Xilinx、Habana、高通和Graphcore也是如此。系统制造商IBM、联想、浪潮、广达电脑、企鹅计算、华为技术、WiWynn、Molex和BittWare也都支持OAM。毫无疑问,其它公司也将效仿它们的芯片和系统——惠普和戴尔显然是缺席的OEM,而富士康和Inventec则是缺席的主要ODM。
通过OAM,加速器被插入一个便携式插座,它的管脚在一侧,然后是一组标准的并行管脚,它在概念上类似于英伟达的SXM2插座,用于Pascal和Volta GPU上的NVLink,从模块上取下并插入主板上匹配的端口中。下图说明了它的原理:
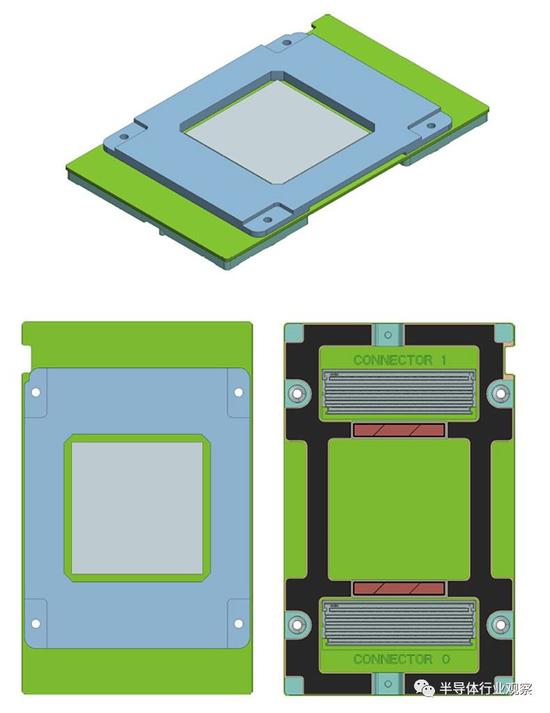
任何插入Emerald Pools机箱的特定加速器都会有散热器,散热器具有不同数量的鳍片和不同的材料,可用于冷却其下方的设备,但高度一致,因此无论哪种加速器插入插槽,散热器都能以一致的方式保持整个机箱中的气流不变。虽然Facebook没有这么说,但没有理由不能将多个不兼容的加速器插入Emerald Pools机箱,并使用该机箱中实现的PCI-Express交换结构相互连接并与主机CPU连接。下图是OAM的外观:

它看起来很像小型汽车电池,不是吗?
每个OAM的尺寸为102毫米×165毫米,足够容纳我们认为未来将会越来越大的多芯片模块。对于耗电量高达350瓦的设备,OAM可支持12伏特的输入;对于需要驱动高达700瓦的设备,OAM可支持48伏特的输入;风冷的散热能力预计将在450瓦左右。当前的OAM规范允许在加速器和主机之间提供一个或两个PCI-Express 3.0 x16插槽,而且很显然,更快的PCI-Express 4.0和5.0插槽已在规划图中。这样就剩下6到7个PCI-Express链路用于交叉耦合加速器。顺便说一句,这些链路可以分成两部分,以提供更多的互连链路,并可以增加或减少任意给定链路的通道数量。
下图是Emerald Pools机箱,里面插了8个加速器中的7个。

Emerald Pools底座后面有四个PCI-Express交换机,位于图片的右侧,每个交换机都插入对应的Angels Landing CPU机箱(即Zion系统的另一半)上的配套PCI-Express交换机。该系统的CPU部分没有在Facebook展位上展出,但Facebook技术项目经理、设计其AI系统的工程师之一Sam Naghshineh在一次演讲中展示了这台机器:

你可以看到,4个PCI-Express 3.0管线从加速器底座和CPU底座上出来,将它们连接在一起。关于Angels Landing有趣的一点不是它总共有4个服务器底座,每个都有一对Xeon SP处理器,这是超大规模数据中心的常规设计。巧妙之处在于,由于在系统的CPU端进行机器学习训练期间,对数据密集处理的需求不断增加,于是它使用处理器上的UltraPath Interconnect(UPI)链接将这4个双插槽机器捆绑在一起,以创建一个8插槽共享内存节点。按照Naghshineh的说法,从技术上讲,这称为扭曲超立方体拓扑:
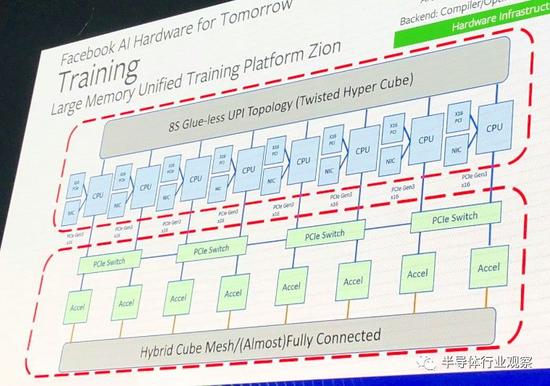
这个大CPU节点设计为拥有2 TB的DRAM主内存,而无需使用大内存条或Optan3D XPoint主内存,而且重要的是,该节点可在系统的CPU端提供足够的内存带宽,从而无需使用HBM内存。(这并不是说英特尔或AMD CPU还拥有HBM内存,但某些场合它们确实拥有HBM内存,尤其是对于HPC和AI工作负载而言。)这8个插槽的DRAM内存带宽和容量一样重要。
如你所见,Angels Landing CPU机箱中的每个CPU都有自己的网络接口卡以及PCI-Express 3.0 x16插槽,用于将CPU连接到PCI-Express交换机结构,该交换机结构将加速器计算复合体连接在一起,并连接到CPU。这些加速器链接在上图中几乎完全连接的混合立方体网格中,但还可以支持其他拓扑,如下所示:
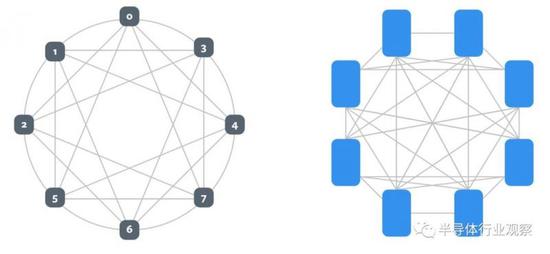
左图中,每个加速器有6个端口,8个加速器连接在一个混合立方体网格中。右图中,仍然有8个设备,但是每个设备都有一个额外的端口(总共7个),这些设备可以按照all-to-all的互连方式进行链接。显然还有其他选择,重点是不同的神经网络在不同的互连拓扑结构中效果更好,这将允许Facebook和其他公司改变互连的拓扑结构,以满足神经网络的需求。
推理的未来
Facebook毫不掩饰地表示,它希望拥有比目前市场上更高效的推理机,这是Facebook去年在一篇论文中讨论的一个话题。在本周的OCP全球峰会上,Facebook公司高层概述了机器学习推理硬件的未来。
Facebook技术和战略主管Vijay Rao提醒大家,早在1980年,英特尔就为8086系列处理器设计了8087数学协处理器,这些处理器如今是客户端的核心芯片和服务器上的Xeon芯片的前身。这些机器可以在2.4瓦的热度范围内实现50 kiloflops(32位单精度),达到相当惊人的每瓦20.8 kiloflops。Facebook的目标是使用像INT8这样的低精度数学运算,来达到接近每瓦5 teraflops,如果你看看英伟达的GV100,它可以达到每瓦特0.4 teraflops。
Rao在他的主题演讲中解释说:“我们一直在与许多合作伙伴密切合作,设计用于推理的ASIC。与传统CPU相比,在加速器中运行推理的吞吐量增加是值得的。在我们的情况下,应该是每瓦特10倍左右。”
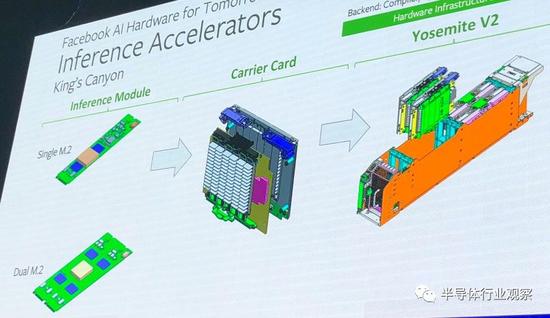
Rao大致谈到了将M.2推理引擎组合到微服务器卡上,然后将它们插入到2015年创建的“Yosemite”服务器机箱中,Facebook设计该机箱是为了完成基本的基础设施工作。但当天晚些时候,Naghshineh实际展示了它的实现方法。以下是M.2推理引擎的“Kings Canyon”系列:

Facebook正试图鼓励推理芯片制造商支持两种不同的形式。一个是单个的宽M.2单元,最大支持12瓦,并带有一个PCI-Express x4接口,另一个具有两倍大的内存、20瓦的热度范围,一对PCI-Express x4端口,可以单独使用或捆绑使用。这些M.2推理卡中的多个被插入“Glacier Point”载卡中,该载卡插入真正的PCI-Express x16插槽,最多可以有4个载卡被插入Yosemite机箱,如下所示:
群集推理引擎的框图如下所示:

这样做的唯一原因与使用低核心计数、高频率、单插槽的微型服务器来运行电子设计自动化(EDA)工作负载相同,英特尔就是这样做的,尽管它想要向世界销售双插槽服务器。推理工作负载类似于Web服务和EDA验证:你可以将整个较小规模的工作分派到大量松散耦合(几乎没有耦合,完全不是真正耦合)计算单元中的一个,然后一次执行大量的这些任务,并同时完成大量工作。对一位数据的推断决不依赖于对无数其他工作的推断。机器学习训练则不同,它更像传统的HPC仿真和建模,在不同的程度和频率下,对一个计算元素进行的任何处理都依赖于其他计算元素的结果。
因此,我们所看到的用于机器学习训练和推理的截然不同的硬件设计都来自Facebook。我们可以肯定的是,Facebook希望能够采用它认为适合框架的任何类型的CPU和加速器进行训练,以及任何价格低廉的芯片推理引擎,在任意给定的时间内,它的性能都比CPU好10倍。今天在Facebook运行在X86服务器上的推理业务是英特尔的失败。或许也未必,没准Facebook会决定在今年晚些时候推出M.2 Nervana NNP推理引擎。我们将会看到推理是如何流过Kings Canyon的。
史海拾趣
|
门禁控制器是门禁系统的核心部分,是门禁系统的灵魂。门禁控制器的质量和性能优劣直接影响着门禁系统的稳定性,而系统的稳定性会直接影响着门禁系统使用者的工作和生活秩序,甚至影响到生命和财产的安全。 目前中国市场上门禁控制 ...… 查看全部问答> |
|
前段时间有朋友问wince的环境搭建方法,由于安装有一些需要注意的地方,直接用语言描述有诸多不便,今天整理了一个图片集,觉得说的比较明白了,需要的朋友看一看,也希望高手朋友们多完善,谢谢! PS: [广告,被屏蔽] 了解更多内容可登陆:[广 ...… 查看全部问答> |
|
XDJM 们: 我现在有一个SIM300的模块,我把这个模块和WinCE的系统的一个COM口接了起来。但是我的这个系统的COM口只有TX和RX,没有其他的DCE和DTE 的管脚。 可是SIM300要求的是traditional DCE-DTE的连接方式。 我现在直接把RTS和CTS连接了起来。 ...… 查看全部问答> |
|
现有一外部中断,中断来临后要求驱动马上读取数据,现在问题是:中断来临后,怎么通知用户主动读取数据,现在我用的是使用了中断上下部,下部处理中断,一产生中断马上进入上半部分处理接收,并传送到用户空间,那么此时的读如果在没有中断时就一直 ...… 查看全部问答> |
|
以前的地址我由于更新网站已经改掉了。 Windows CE实用开发技术 电子档下载。 版权说明,本电子档版权归原书作者所有,下载仅供学习,请与下载后24小时删除。 保护合法版权,请购买正版书籍! 请勿多线程,保护本空间的速度! 谢谢!! 下载 ...… 查看全部问答> |
|
如题,因为WinCE系统自带的Word Viewer是不能够进行新建和编辑的只能用来浏览Word文件,而且我试过插入一个图片和表格在Word Viewer中也能正常显示出来,因为本人现在急需一个也能在WinCE上面进行新建和可编辑的Word(当然插入表格和图片也是可以的 ...… 查看全部问答> |