



历史上的今天
今天是:2025年01月13日(星期一)
2020年01月13日 | 基于stm32f4的高速信号频谱分析仪的设计与实现
2020-01-13 来源:elecfans
摘 要
本系统是以STM32F407为核心,主要采用FIFO来做高速缓存。高速信号先通过AD采样,然后先将采样后的数据给FIFO先缓存处理,然后再通过STM32F407进行加Blackman预处理,再做1024个点FFT进行频谱分析,最后将数据显示在LCD12864上,以便进行人机交互!该系统可实现任意波形信号的频谱显示,以及可以自动寻找各谐波分量的幅值,频率以及相位并进行8位有效数据显示。
系统设计任务
一、任务
设计并制作一个高速频谱分析仪。
1系统方案
本系统由前置匹配放大电路,AD采样电路,高速FIFO缓存电路,以及液晶显示电路组成。其中高速数据缓存电路,以及高精度的显示数据是本次设计的难点!下面分别论证这几个模块的选择。
系统框图
1.1测量方法的论证与选择
1.1.1 MCU处理器的比较与选择
做DSP处理主要是要考虑到运算速度。
在处理器的选择上通常可以采用8位,16位或者32位的MCU,但由于在处理信号的过程中,通常会遇到快速傅里叶FFT算法,所以会遇到大量的浮点运算,而且一个浮点数要占用四个字节,故在处理过程中要占用大量的内存,同时浮点运算速度比较慢,所以采用普通的MCU在一定时间内难以完成,所以综合考虑运算速度和内存大小等因素。
本系统采用32位的STM32F407做为核心DSP处理器件,该芯片具有1MB的Flash闪存空间,196KB的SRAM空间,并且时钟频率达到了168MHz。程序运行于168MHz主频时,通过Flash取指令(不是内部SRAM),通过Dhrysone测试得到210DMIPS,主要采用ART加速器,可以最大限度的消除Flash存储器较慢从而限制MCU性能的发挥,这可以使CPU可以在所有工作频率下近乎零等待的方式,从Flash中运行程序。还有就是STM32F407带有硬件FPU处理单元,这样可以不用软件算法实现浮点运算,而直接采用硬件来实现浮点运算,这样就减小了编译器生成的代码量,并且使用更方便,浮点数只占用四个字节就可以表示的数据范围很大,因此不用担心计算后的数据溢出问题!进一步提高运算速度。
1.1.2 采样方法比较与选择
方案一 通过DDS集成芯片产生一个频率稳定度和精度相当高的方波信号作为时钟信号。
可选用直接数字频率合成(DDS)芯片AD9851,AD9851为ADI公司生产的高性能器件,可与单片机通过简单的接口完成串行或者并行通信。可完成外部输入频率控制字与芯片内部频率相位控制字之间的转换,可以非常容易的通过频率控制字调整输出频率,以及精确的调整输出信号的相位,输出信号幅值稳定,但是由于DDS控制也需要占用一部分MCU的IO口资源,并且DDS在价格上成本有点高。
方案二 直接由MCU产生PWM波做为采样时钟信号。
可直接由STM32F407产生的PWM波,可实现频率,占空比可调的方波。最快IO口翻转速度可以达到84MHz,可以轻松实现想要的采样频率。由于输出的是3.3V的幅值的电压,与外围芯片相连,需要经过电平转换芯片转成5V,才能作为外围芯片的时钟信号。
方案三 采样时钟信号选用Linear公司生产的LTC1799提供。
LTC1799是一款精准型振荡器,使用方便。它采用2.7V到5.5V单电源工作,并提供了轨至轨、占空比为50%的方波输出。CMOS输出驱动器确保了快速上升/下降时间和轨至轨开关操作。频率设定通过电阻器调节,电阻阻值在 的范围内变化,以选择处于100KHz到33MHz之间的任何一个频率。三态DIV输入负责决定驱动输出之前对主时钟进行1、10或100分频。
综合上述方案,选择方案三,采用一片LTC1799来产生15MHz的采样时钟信号。
1.1.3 AD采样芯片的论证与选择
方案一 采用MCU内部ADC对采样信号进行采样。
STM32F407内部最大转换速率为7.2MSPS,而且被采样信号的幅值只能在0V到3.3V之间,能测得动态范围小,难以满足要求。
方案二 采用TI公司的8位TLC5510A作为AD采样芯片。
TLC5510A是采用高速CMOS技术,8位的,最大转换速率为20MSPS的AD转换芯片。支持+5V电源供电,内部包含采样保持电路,输出带有高阻态模式,以及带有内部参考电阻。输出数据在时钟的下降沿有效,数据流水线结构导致了2.5个时钟的延时。而且高速AD普遍价格比较昂贵,在满足输入信号在2V以上动态范围,TI公司可供申请的高速AD芯片只有TLC5510A这一种。
综合上述方案,选择方案二,在精度要求不高场合,采用TLC5510A作为高速采样芯片。
1.1.4 高速数据缓存芯片的论证与选择
由于15MHz的高速数据流,如果中断来标记数据流的地址,由于MCU的中断响应时间有限,有12个时钟周期的中断延时,因此就需要外部存储器做高速数据缓存。
方案一 采用SRAM芯片作为外部高速数据缓存芯片。
采用IDT71024来做高速缓存,由于SRAM提供了地址线端口和数据输入和输出端口,如果用MCU来控制的SRAM的地址线,中断响应不过来是反应不过来,如果用计数器作为地址计数器,原理是可以,但是实际操作效果不佳。
方案二 采用FIFO芯片作为外部高速数据缓存芯片。
IDT7205是单向异步FIFO的典型芯片,由IDT公司生产的,是一种高速、低功耗的先进先出双端口存储缓冲器。这种FIFO芯片内部的双端口RAM具有2套数据线,分别执行输入和输出功能,各自独立的写读指针分别在写、读时钟的控制下顺序地从RAM中写、读数据。
综合上述方案,选择方案二,它无地址线,布线简单,只能是顺序存取。
系统理论分析与计算
2.1快速傅里叶变换(FFT)
DFT(离散傅里叶变换)是数字信号分析与处理中的一种重要变换,它可以使数字信号处理可以在频域内采用数值运算的方法进行,大大增加了数字信号处理的灵活性,但直接计算DFT的计算量与变换区间长度N的平方成正比,当N较大时,计算量太大,所以在快速傅里叶变换(FFT)出现以前,直接用DFT算法进行谱分析和信号的实时处理是不切实际的。
DFT的定义:设 是一个长度为N的有限长序列,定义 的N点离散傅里叶变换为

能提高DFT速度的唯一可利用的是因子 。 称为旋转因子![]() ,
,![]() 可表示为
可表示为 具有以下两个重要性质。
具有以下两个重要性质。
①对称性
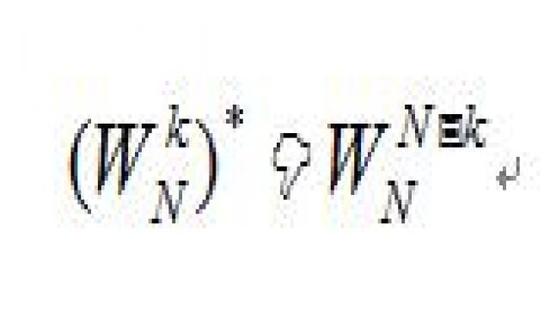
②周期性
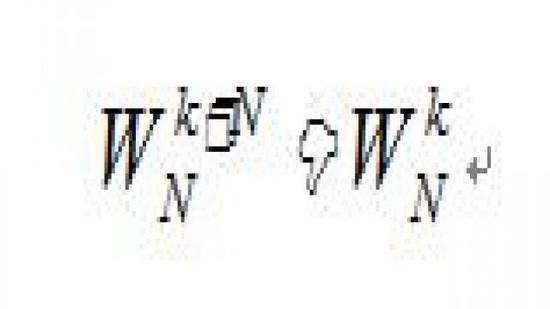
利用 的周期性和对称性可把DFT的计算次数大大减小。
DFT分解法基本上分为两类:一类是将时间序列X(n) (n 为时间标号)进行逐次分解,由此得到的FFT算法称为按时间抽取算法,另一类是将傅里叶交换序列X(k) ( k为频率标号)进行分解,叫做按频率抽取算法。对每一算法,按基本的蝶形运算的构成又可分为基2、基4、基8以及任意因子等的FFT算法。不同基的FFT算法所需的计算量略有差异。之所以说略有差异是指并无数量级上的差异,甚至无成倍的差别。只是某种基的算法比另一种省几分之几而已。
而本方案采用的就是ST公司官方固件库里DSP库中已经写好的关于FFT的库函数,调用的是基4复数序列1024个点的FFT函数库。
假设FFT之后某点n用复数![]() 表示,那么这个复数的模就是
表示,那么这个复数的模就是![]() ,相位就是
,相位就是![]() ,频率就是
,频率就是![]() ,(其中N表示FFT要做的点数,n表示排序的点,Fs为采样频率)。根据以上的结果,就可以计算出n点
,(其中N表示FFT要做的点数,n表示排序的点,Fs为采样频率)。根据以上的结果,就可以计算出n点 ,
,
所对应信号的表达式为: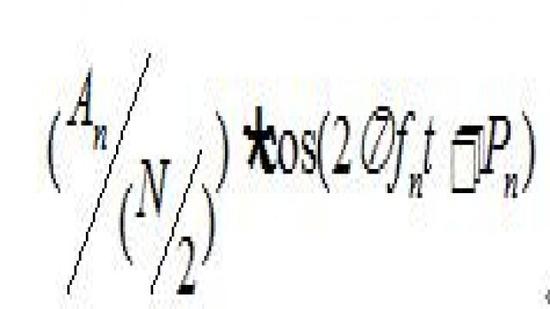
而对于n=1的点信号,是直流分量,幅度即为: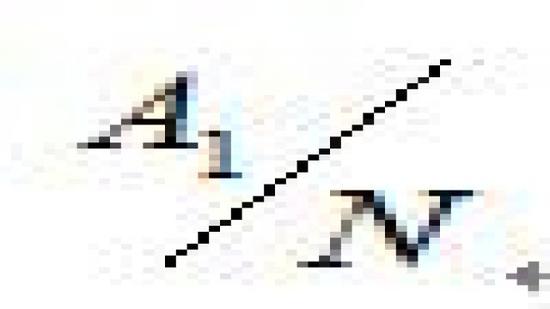
因此对于直流量要特殊考虑,一是幅值是其它频率点的2倍,二是直流量不含有相位信息。
但是由于所做的点数有限,其会造成频谱泄露是必然的。因此并非要计算所有点的幅值,相位以及频率信息,而只需要计算出各个峰值点的幅值,相位以及频率即可表示采样信号各谐波分量的全部信息。
因此算法模块要实现的功能:保存FFT之后峰值点的实部和虚部,以及峰值点所处的位置这几组点即可。
2.2窗函数的分析与计算
在频谱分析过程中,加窗是提高信号分析精度的一个重要措施,对加窗函数的基本要求:时域为改善截断处的不连续状态(由于吉布斯现象造成的振荡);频域为窗谱的主瓣窄而高,以提高分辨率,旁瓣幅值应小,正负交替接近相等,以减小泄露和假频。因此在选择窗函数的时候,应考虑被分析信号的性质和处理要求,如果仅要求精确求出主瓣频率,而不考虑幅值精度,则可选择用主瓣宽度比较窄而便于分辨的矩形窗,例如测量物体的自振频率等;如果分析窄带信号,且有较强的干扰噪声,则应选用旁瓣幅度较小的窗函数,如汉宁窗(Hanning)等。
为了使加窗函数后的功率谱和幅值谱不受窗函数的影响,必须根据一定的原则推导出恢复系数。加窗后的恢复系数一般遵守两个原则之一:幅值相等或能量相等的原则。
因此加窗模块要实现的功能:提高采样信号分析的幅值精度。
频谱分析中恢复系数的使用原则
在频谱分析中,根据不同用途采用不同恢复系数,在进行倍频程和三分之一倍频程分析时,为了使频带内总能量不变,一定要采用能量相等的恢复系数;而进行谱分析时,更关心的是各峰值频率对应的幅值,此时只能采用幅值相等的恢复系数。
常用的各种窗函数的恢复系数


2.3 A/D采样的分析与计算
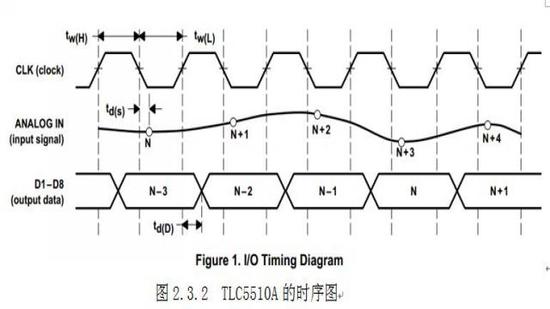
本系统采用的AD转换芯片为TLC5510A,TLC5510A是采用高速CMOS技术,8位的,最大转换速率为20MSPS的AD转换芯片。支持+5V电源供电,内部包含采样保持电路,输出带有高阻态模式,以及带有内部参考电阻。输出数据在时钟的下降沿有效,数据流水线结构导致了2.5个时钟的延时。虽然AD转换数据输出有2.5个时钟延时,但是只要量化的结果是正确的和数据是顺序输出,这个数据输出延时我们可以不用关心。外部还需要接一个4V的参考电压,这样才能量化到0V~4V的输入信号。TLC5510A引脚图和时序图如下:

图2.3.1 TLC5510A的引脚图
引脚功能描述:

由于TLC5510A的最大转换速率只有20MHz,根据采样定理,采样率 ,(其中 Fs为采样速率,Fh为被采样信号的最大上限频率),才能有效地避免频谱混叠现象。因此输入的被采样信号的上限频率不得高于10MHz。因此本次方案选定的采样频率为15MHz,即被采样信号的上限频率不得高于7.5MHz。
,(其中 Fs为采样速率,Fh为被采样信号的最大上限频率),才能有效地避免频谱混叠现象。因此输入的被采样信号的上限频率不得高于10MHz。因此本次方案选定的采样频率为15MHz,即被采样信号的上限频率不得高于7.5MHz。
通常称两条谱线之间的距离为频率分辨率,对于FFT进行频谱分析来说,数字频谱分辨率为: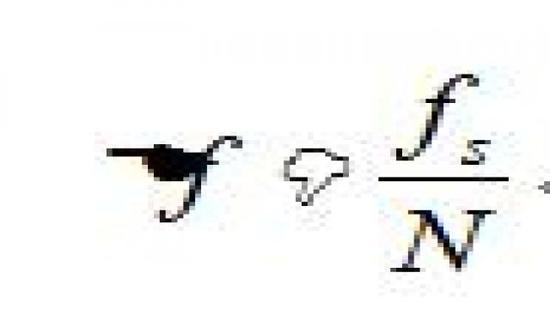
式中,N为FFT的长度。我们这里N只做了1024个点的,因此对输入的被采样信号最小频率分辨度为 ,由于FFT之后就可以计算出信号的幅度谱,将幅度谱平方得到功率谱。
,由于FFT之后就可以计算出信号的幅度谱,将幅度谱平方得到功率谱。
其计算公式为: .因此A/D转换芯片的输入信号范围为15KHz~7.5MHz之间了.
.因此A/D转换芯片的输入信号范围为15KHz~7.5MHz之间了.
2.4 高速缓存的分析与计算
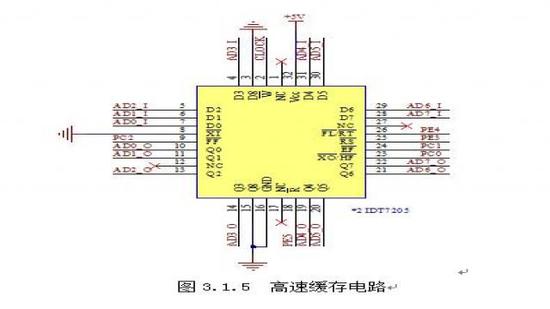
本系统的高速缓存芯片采用的是IDT公司生产的IDT7205,其引脚图如图2.4.1所示,其读写时序图如图2.4.2


IDT7205简介:
IDT7205是8位的FIFO芯片,容量为8192*9bit,存储时间为12ns,有空、半满、满三个标志位。最大功耗为660mW,工作电压为+5V。D0~8是数据输入总线,Q0~8是数据输出总线,R 、W 是读、写控制端,XI 、 XO是级联控制端,HF 是FIFO状态满标志,FF 是FIFO状态空标志。根据HF 、FF 状态,写处理器就可以知道FIFO是否已满,根据状态读处理器就可以知道是否有数据
IDT7205提供一个比特位由用户选择用于控制或者奇偶效验的,同时提供重传(RT )功能。它使用内部指针载入和取出数据,数据的输入和读出是由写(W )和读(R )控制。该器件使用满标志(FF )和空标志(EF )以防止数据的上溢和下溢,半满标志(HF )用于通信控制。(RS )是用于复位。通过它的扩展逻辑可以进行无限制的深度和宽度扩展,这样就可以方便地扩展适于总线读写操作的各种容量的16或32位的数据存储缓存区。
IDT7205是单向异步FIFO的典型芯片。是一种高速、低功耗的先进先出的双端口存储缓冲器。基本时序及功能逻辑为:RS 引脚置低时,IDT7205复位。内部读写指针都被复位到起始位置了,每一次上电后必须要将RS 置为低电平后方可执行写入操作。当RS 复位后R 和 W必须为高,直到 RS变为高电平后才能有所变化,进行读写操作。若数据满标志FF 没有变低,那么每次W 引脚置低,就执行一次外部数据写入操作,内部写指针自动加1,数据顺次进入FIFO中。当缓存区写满一半(4KB)的时候,下一次 W低电平将使半满XO/HF中间指示 置低,表示缓冲区间已存满一半的可用空间,该信号可以提前提醒系统机进行读数据操作。为了避免数据写入溢出,当最后一个W 的下降沿时,内部满标志FF 置低,它将禁止写入操作,FF 有效期间,内部写指针不再移动,直到进行一次有效的读操作后满标志FF 才会被消除。若内部空标志 EF没有被置低,那么每当读允许R 置低时,就执行一次内部数据的读出,内部读指针自动加1,数据就顺次从FIFO中读出来。为了避免数据空读,当所有数据被读出的,内部空标志EF 被置低,将禁止读出操作,EF 有效期间,内部读指针不再移动,读出数据总线为高阻抗状态,直到进行一次有效的写操作后,空标志EF 才会被消除,IDT7205的RT/FL 是一个复用输入脚,在深度扩展时有用,在单片使用时,它作为一个重传数据引脚,负脉冲有效。一个重传操作将读指针回到首地址,不影响写指针地址。
从图2.4.2可以看出,IDT7205的有效数据都在读写时钟的上升沿到来时有效,然而从图2.3.2 TLC5510A的时序图看出,有效数据在时钟的下降沿到来时有效,因此在进行时钟同步的时候,要对IDT7205的写时钟要进行一次反相才可以。本系统采用与非门74LS00做为反相器。如图2.4.3所示,我们可以算出此与非门的保守最高工作频率为:

因此,74LS00可以应用到本系统中。

2.5液晶显示模块的分析与计算
本系统的液晶显示模块采用LCD12864来显示。
显示模块采用LCD12864点阵蓝底白字液晶显示模块,可显示汉字及图形,可与CPU直接接口。具有多种功能:光标显示、画面移位、睡眠模式等。
在显示字符时,首先输出的是它最左边的像素,也就是第一列像素,且高位在下,低位在上然后输出第2列、第3列,每一列8位(1个字节)。
由于LCD12864是由64*64左半屏和右半屏构成的,通过设置CSA和CSB为10和01可分别选择左半屏和右半屏进行显示操作。通用显示函数的参数为P、L、W、*r,它们表示从第P页(X地址)开始,在左边距L的位置开始显示W个字节,字节缓冲地址为r。
RS=0时选择命令寄存器,RS=1时选择数据寄存器。
这个模块主要实现的功能是:将1024个点的FFT后的,得到的是输入信号的频谱,由于频谱的偶对称图形,因此只需要显示512点的频谱分析,就可以得到我们想要的频谱信息,由于LCD12864只能一次性显示128列,因此我们要分5次显示,才能能显示512列所包含的信息。还要利用算法,来显示输入信号的各个谐波分量的幅值,频率以及相位信息。
LCD12864引脚说明:

本系统在+5V供电电压下工作,因此输入级运放也采用+5V单电源工作,这导致静态直流电压在2.5V左右(这个理论上应该设置在2V,以备接收最大输入信号的动态范围),由于输入的信号在0~4V之间,因此输入信号的最大幅值为2V,所以经过1024的点FFT之后,极限计算幅值分为2种情况考虑为:1.直流量为1024*2.5=2560 2.交流量为512*2=1024
在LCD12864上显示出这些数值,但一列只有64个点格,因此只能让一格表示为 .
.
2.6前置匹配放大分析与计算
本系统的前置匹配放大采用TI公司生产OPA820,其具有高增益带宽积,低输入噪声,并支持单电源供电。其电路原理图如图2.6.1所示。

该模块主要实现功能为,匹配信号源50欧姆输入阻抗,并实现对交流放大,并隔离直流放大,同时利用运放的低输出阻抗,提高了信号的分析精度。
运放的同相端有两种信号频率:1.为直流偏置电压 2.为输入信号非直流信号电压
因此此模块输出与输入之间的电压关系的表达式为:

3.电路设计与程序设计
3.1电路设计
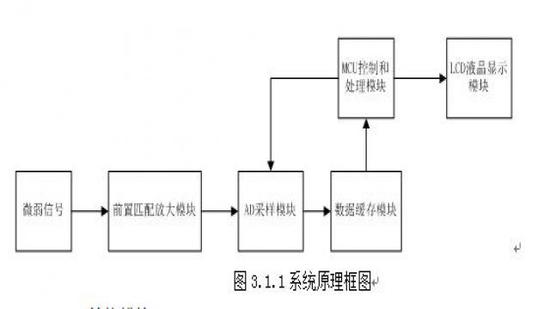
3.1.1系统总体框图
系统总体框图如图3.1.1所示:
3.1.2 A/D转换模块原理图
A/D转换使用的是TI公司生产的8位精度的并行AD转换器TLC5510A。其电路原理图如图3.1.2所示

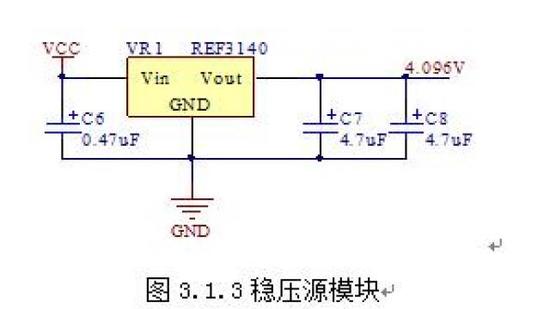
3.1.3稳压源模块原理图
基准稳压源芯片使用的是TI公司生产的REF3140,可以稳定电压到4.096V。其电路原理图如图3.1.3所示
3.1.4 时钟振荡模块原理图
时钟振荡芯片所提供的采样时钟信号选用Linear公司生产的LTC1799提供。其电路原理图如图3.1.3所示

LTC1799的典型应用如图3.1.4所示。

1脚接电源,2脚接地,3脚与电源直接电阻 ,可通过调节 来调节输出的频率,4脚为DIV脚,选择分频系数,5脚为输出。
3.1.5高速缓存模块原理图
本系统高速缓存芯片选用IDT司生产的IDT7205,其存储深度可以达到8KB。其电路原理图如图3.1.5所示
3.1.6液晶显示模块原理图
本系统液晶模块采用无字库LCD12864来显示,其电路原理图如图3.1.6所示。

在数字信号处理最重要的就是要验证数据的准确性和有效性,因此就要用MATLAB软件仿真来做数据对比,以判断STM32F4的计算结果是否准确。
在测试过程中,我们使用被白噪声污染过的信号经过离散化后的数组,在MATLAB上做1024个点FFT处理之后所得的数据图形,如下图所示。经和STM32F4处理后的数据比对发现完全一致。

下图为同一信号256与1024点FFT之后数据的对比:

由于处理的数据都是浮点型,而且所得到的数据的动态范围比较大,因此就会涉及小数点的移动显示的问题,传统对小数点的显示采用的是定点显示,即固定小数点在液晶显示屏的位置来显示数值,一旦遇到数量级跨度很的数值时,很浪费液晶显示占用的空间,因此本系统通过算法实现浮点显示,即占用固定的显示空间,小数点随数值大小浮动显示。
在IAR编译器里编程的时候有几点问题要值得注意:
1.编译优化等级的问题
在内存空间充足的情况,最好不要对程序进行优化,很可能让程序运行出现问题。优化等级选为None即可。

2.程序路径添加以及预编宏定义的问题
在引用ST官方提供的库函数的.c文件时,只要是不在 文件所处位置下的.c文件都应该要在编译器选项里添加路径,其中$PROJ_DIR$指的是带 文件所处位置。
$PROJ_DIR$.. 是指工程文件即 文件所处文件的上一个文件夹。
而$PROJ_DIR$....是指工程文件即 文件所处文件的上一个文件夹再上一层文件夹依此类推。
在使用FPU处理时首先要对FPU进行预编宏定义,这个在arm_math.h文件里提到了。
__FPU_PRESENT=1
__FPU_USED=1
注意不要预编宏定义里不要有空格出现,否则会出现编译错误。
浮点运算一直是定点CPU的难题,比如一个简单的1.1+1.1,定点CPU必须要按照IEEE-754标准的算法来完成运算,对于8位单片机来说已经完全是噩梦,对32为单片机来说也不会有多大改善。虽然将浮点数进行Q化处理能充分发挥32位单片机的运算性能,但是精度受到限制而不会太高。对于有FPU(浮点运算单元)的单片机或者CPU来说,浮点加法只是几条指令的事情。
现在又FPU或者硬件浮点运算能力的主要有高端DSP(比如TI F28335/C6000/DM6XX/OMAP等),通用CPU(X87数学协处理器)和高级的ARM+DSP处理器等。
STM32-F4属于Cortex-M4F构架,这和M0、M3的最大不同就是多了一个F-float,即支持浮点指令集,因此在处理数学运算时能比M0/M3高出数十倍甚至上百倍的性能,但是要充分发挥FPU的数学性能,还需要一些小小的设置:
1.编译控制选项:虽然STM32F4XX固件库的例程之system_stm32f4XXX.c文件中添加了对应的代码,但给用户评估使用的STM32F4-Discovery例程中却没有,因此编写浮点运算程序时,虽然编译器正确产生了V指令来进行浮点运算,但是因为system_stm32f4XXX.c文件没有启用FPU,因此CPU执行时只认为是遇到非法指令而跳转到HardFault_Handler()中断中原地踏步。因此要保证这个错误不发生,必须要在system_init()函数里面添加如下代码:
/* FPU settings ------------------------------------------------------------*/
#if (__FPU_PRESENT == 1) && (__FPU_USED == 1)
SCB->CPACR |= ((3UL << 10*2)|(3UL << 11*2)); /* set CP10 and CP11 Full Access */
#endif
因为这个选项是有条件编译控制的,因此需要在工程选项(Project->Options for target "XXXX")中的C/C++选项卡的Define中加入如下的语句:__FPU_PRESENT=1,__FPU_USED =1。这样编译时就加入了启动FPU的代码,CPU也就能正确高效的使用FPU进行简单的加减乘除了。
但这还远远不够。对于复杂运算,比如三角函数,开方等运算,如果编程时还是使用math.h头文件,那是没法提升效率的:因为math.h头文件是针对所有ARM处理器的,其运算函数都是基于定点CPU和标准算法(IEEE-754),并没有预见使用FPU的情况,需要很多指令和复杂的过程才能完成运算,也就增加了运算时间。因此要充分发挥M4F的浮点功能,就需要使用固件库自带的arm_math.h,这个文件根据编译控制项(__FPU_USED == 1)来决定是使用那一种函数方法:如果没有使用FPU,那就调用keil的标准math.h头文件中定义的函数;如果使用了FPU,那就是用固件库自带的优化函数来解决问题。
在arm_math的开头部分是有这些编译控制信息:
史海拾趣
|
扩展汽车电子控制网络应用 随着汽车电子产品比例越来越大,轿车中的电子元件、器件、模块部件和多种电机越来越多,线束也越来越长,越来越复杂,这必然造成严重的电磁干扰,使系统的可靠性下降。而取代传统线束的最佳方案是采用信息交换迅速、高 ...… 查看全部问答> |
|
1.正确选用由于ABS系统较常规制动系统更为复杂,因此在选用、更换及补充制动液时应特别注意:(1)在ABS系统中,制动液的通路更长、更曲折,致使制动液在流动过程中受到的阻力较大;另外,在ABS系统中,运动零件更多、更精密,这些运动零件对润滑的要 ...… 查看全部问答> |
|
目录: 第一章 集成运算放大器的基础知识 §1-1 集成运算放大器的基本构成和表示符号 §1-2 理想运算放大器及其等效模型 §1-3 集成运算放大器的特性参数及分类 §1-4 集成运算放大器的实际等效模型 §1-5 集成运算放大器特性参数的测试方 ...… 查看全部问答> |
|
本信息来自合作QQ群:NXP Cortex-M0/M3交流(87394268) 我建立了两个工程,一个是用来做IAP的,另一个是应用程序,当应用程序自己跑的时候就没有问题, 当把应用程序和IAP程序连在一起跑的时候,运行一段时间就进了异常 ...… 查看全部问答> |
|
AD8320简介 AD8320是一款数字控制式可变增益放大器,并针对同轴线路驱动应用进行了优化。所需输出增益由8比特串行字决定,输出增益范围为36 dB(256增益级)。此外还提供线性增益响应。 我的图是按AD8320的数据手册上的Figure 45.B ...… 查看全部问答> |
|
这是一个430使用者的笔记,写的很好很详细,值得珍藏学习的!!! [ 本帖最后由 鑫海宝贝 于 2011-10-12 09:36 编辑 ]… 查看全部问答> |
|
简单来说嵌入式就是在专有的硬件设备上写程序,那从事嵌入式软件开发有什么好处呢?下面由卓跃教育为大家介绍。 最近几年来,中国的嵌入式软件发展速度一直高于中国软件产业的发展速度和全球嵌入式软件的发展速度,在中国软件产业和全球嵌入式软 ...… 查看全部问答> |