



汽车智能座舱测评方法研究
2025-12-03 来源:智能汽车设计
摘要:汽车智能座舱的功能体系十分庞大、功能点比较分散,设计一种有效的测评模型,在座舱软件的迭代、发布准出流程中有较高的应用价值。文章从智能座舱功能拆解、测评模型设计、测试方案制定、模型的实际应用等几个维度,对座舱测评方法做了深入的研究,并给出一套可行的测评方案。具体将智能座舱划分为座舱控制、视觉、智能辅助驾驶交互、娱乐和导航、智能语音和系统级应用六个功能模块,从功能性、性能/稳定性、用户体验、兼容性、安全性五个维度对座舱功能进行评价,采用二维权重和一维权重相结合的方法,对每个细分功能点进行评分,最终计算出座舱整体的总评分。
随着软件定义汽车的高速发展,智能座舱在乘用车上的普及率逐年提高,为用户提供高品质的影音娱乐体验。当前座舱功能已经非常强大并高度集成,但是功能迭代并没有止步,以持续满足用户不断增长的舒适体验需求。如何在快速迭代升级的同时,以有限的测试资源保证软件交付的质量,已经成为主机厂的痛点。随着汽车 E/E架构硬件由分布式向域控制-中央集中式不断升级,座舱域控制器的重要性凸显,而座舱域作为交互的核心和智能驾驶域之间的纽带,是体现和提升驾乘感受的重要组成部分[1]。
近年国内智能座舱的新车配置渗透率高速增长,从2020 年约为48.8% [2],到2025 年初已经达到75%以上(根据盖世汽车研究院的统计数据)。中国汽车工程学会将座舱发展分为Level0-Level4 5 个级别,从传统座舱逐步发展为全感知智能座舱[3]。本文将智能座舱的发展过程,理解为三个不同的阶段:一是大量的液晶屏布局阶段,具有大尺寸中控液晶屏,全液晶仪表盘,中控屏与仪表盘一体化设计,新增抬头显示系统(Head-UpDisplay, HUD)、流媒体后视镜等[4];二是人机交互体验强化阶段,人机交互(User Interface & UserEXperience, UI&UX)体验的精细打磨,用户界面的舒适度、流畅度、美观度不断提升,舱内立体声(如杜比音效)的实现,语音识别能力的引入,导航、娱乐功能的引入;三是人工智能生成内容(Artificial Intelligence Generated Content, AIGC)逐步引入阶段,具有超强的车机端算力和云端算力,得以将人工智能(Artificial Intelligence, AI)和大模型引入座舱,实现更加智能、拟人的多模态交互,高度智能化的语音系统[5],利用AI 实现用户习惯分析和自学习。AI 技术可能会成为座舱技术创新的下一个争夺点。
本文将智能座舱划分为6 个功能模块,结合5种评价维度,设计了一种测评模型,最后通过实际应用,验证模型的有效性。
1 智能座舱功能模块划分
座舱的软件研发流程从传统的V 模型逐步转变为敏捷开发模型,V 模型如图1 所示,敏捷开发模型如图2 所示。V 模型适合需求变化相对不大,同时对软件质量有极高要求的场景;敏捷开发适合需求变更和迭代的变化量大、速度快,同时质量要求也比较高的场景。模型都有各自的优缺点,智能座舱项目组可以在不同发展阶段,选择最符合团队需求的模型,应对市场的挑战。
智能座舱不同的业务模块、测评方案存在较大的差异,深入了解各模块的功能,对于制定合理的测评方案至关重要,基本业务架构如图3 所示。郁淑聪等提及了一种基于用车情景的座舱功能点[6],这种方法比较适用于实车座舱测评;晏江华等提及了一种基于主客观指标测评进行融合的智能座舱测评系统[7]。本文按照功能域将座舱划分为6 个模块。
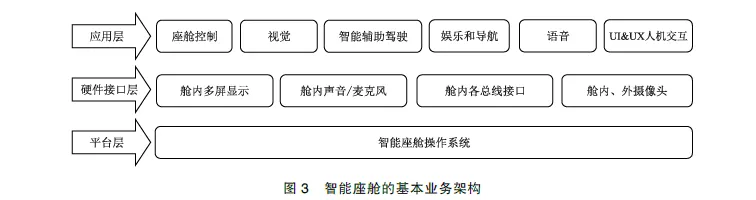
1.1 座舱控制模块
座舱控制模块主要包括空调、门窗锁、内外灯光等,在中控屏上使用各种类型的软开关,代替传统机械开关对车辆进行设置和控制。这部分功能多为各类基础功能的设置项,用户使用率较高,会随着车身域功能的更新和优化进行迭代。
1.2 视觉模块
视觉模块功能主要分为基础影像(如泊车影像)和多模态识别(如FaceID 人脸识别)两类,结合汽车内、外部的多种摄像头实现。通过摄像头数量的增加和视觉算法能力的提升,大量扩展了环境感知功能,比如哨兵模式、人脸识别等,为用户提供更可靠的安全守护。
1.3 智能辅助驾驶交互模块
智能辅助驾驶交互模块(Advanced Driving Assistance System Human Machine Interface, ADHMI)随着近年智能辅助驾驶功能的高速发展衍生而来,辅助驾驶系统没有显示屏的渲染能力,所以驾驶信息需要借助智能座舱的渲染能力,准确传达给驾驶员,比如道路环境感知信息和辅助驾驶引导信息等,增强辅助驾驶安全。
1.4 娱乐和导航模块
娱乐和导航模块主要为用户提供各种影音娱乐功能,包括在线音乐、在线视频、蓝牙电话/音乐、车机手机互联等,以及车载导航,多以安卓系统的App 应用形式实现(第三方应用的形式居多)。娱乐模块在用车过程中提供了丰富的影音体验;导航模块为驾驶员提供路线引导,方便出行。
1.5 智能语音模块
智能语音模块以语音对话作为人机交互接口,实现驾驶员和乘客在舱内通过语句指令方式操控车机实现各种功能,比如打开空调、座椅加热等。除了基础控制能力,随着AI 能力的引入,语音系统配合不同的用车场景实现更多智能化、拟人化的功能。
1.6 系统级应用模块
系统级应用模块为座舱提供基础支撑的作用,比如驾驶信息显示、远程升级(Over The Air,OTA)等。功能显性程度不高,但是在性能、稳定性、安全漏洞上有很高的要求。比如OTA 远程升级的成功率有极高的标准(一般在99.99%以上),升级问题可能会导致座舱主机开机故障,影响用户驾驶。
2 智能座舱测评模型设计
李辉等将软件功能测试描述为根据产品特性及用户场景,测试产品特征,以判断其是否满足设计需求[8]。智能座舱是用户与车的主要交互接口,包括UI&UX 交互、声音交互、语音交互、手势交互、面容交互等,是用户接触最密切、使用频率最高的模块之一,其体验的优劣对用户产生的直接影响很大;同时为了满足用户日益增长的舱内舒适体验需求,功能的新增、升级、迭代频率也很高,所以敏捷开发模型是当前的主流方案。高效、可行的测评方案对于高质量实现敏捷开发过程至关重要。
2.1 测评模型设计
郁淑聪等提出的基于驾驶员的座舱测评模型,功能维度和测评指标都是三维深度,该模型能够有效地进行座舱测评[6],但是由于维度较深导致总体计算方法偏复杂。本文结合座舱的功能特性以及评价维度,设计了一种评价模型,如图4所示。模型从6 个功能模块出发,进一步拆分为细分功能点,采用多维度评价体系,对座舱功能进行尽可能完整的测评,最后得出综合评分。通过设定合理的评分指标,对座舱软件的总体质量把关,在敏捷开发、迭代、释放过程中,对问题进行有效拦截。主要设计原则是保证得到有效测评结果并尽可能降低计算复杂度。
2.2 座舱细分功能点
座舱细分功能点存在不同的颗粒度划分方法,功能点量级可以达到上千。在每个功能模块下,列举比较典型的5 种细分功能(可以按需扩展)如表1 所示,避免模型过于庞大,保证测评工作的复杂度适中。细分功能颗粒度,是基于支撑用户实现完整的功能体验为出发点,比如座舱控制模块中的灯光,包含了前后大灯、照明灯、氛围灯等全部功能。

2.3 评价体系和测评方案
2.3.1 评价体系
以功能体验为核心,对各细分功能点进行5个维度的评价,包括功能性、性能/稳定性、用户体验、兼容性、安全性,如图4 所示。随着座舱功能的迭代和发展,评价维度也可以相应做出调整,具有可扩展性。
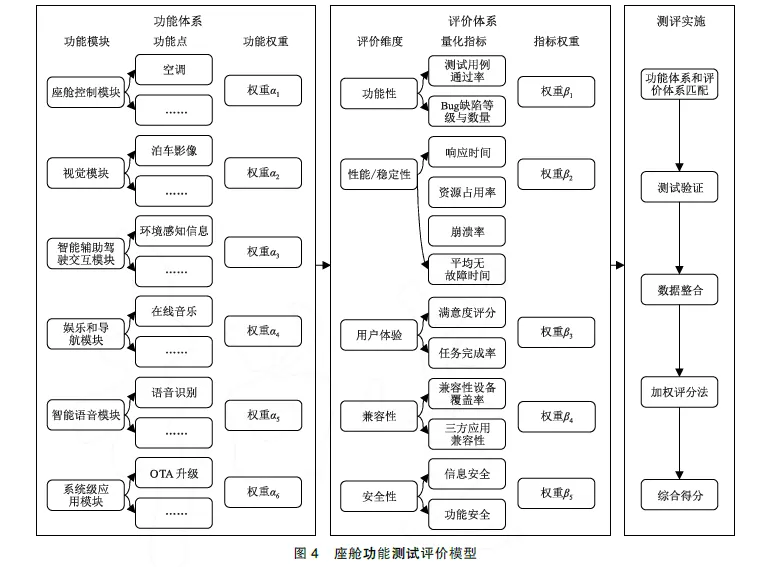
2.3.2 功能测试
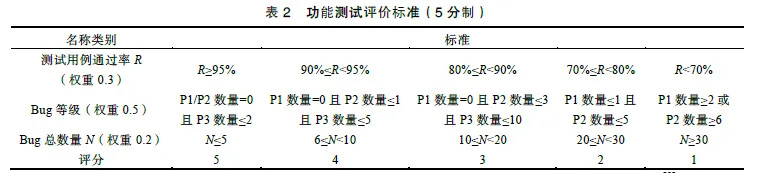
目标是依据需求文档,检查各项功能的实现完整度,测试流程包括需求评审、需求分析、测试用例设计和执行、创建Bug、验证Bug、回归测试等。功能测试是座舱测评中比较核心的环节,占用资源较多。测试方案设计的核心要素是功能拆解和测试用例设计,不同功能对应的测试方案差别较大。测试用例设计,一般是以尽可能少的用例覆盖尽可能多的场景:1)满足最基本功能实现的场景;2)较常见的交互条件下的场景;3)不太常见的交互条件下的场景;用例等级按照重要度从高到低依次定为P0、P1、P2,数量设置参考举例:P0 为10%,P1 为25%,P2 为65%。用于测试用例执行的环境,一般有小型硬件在环测试(Hardware In the Loop, HIL)台架,大型整车HIL 台架,实车;不同功能点需要合理选择测试环境,有利于测试高效实施。功能性评价指标,取决于测试用例通过率、Bug 等级和数量(Bug等级分为P1-P4 四个级别,其中,P1 为致命级别,P2 为严重级别,P3 为一般级别,P4 为轻微级别),评分标准如表2 所示。对于细分功能点,功能性测评得分Sf计算方法为
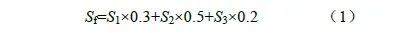
式中,S1为测试用例通过率得分;S2为Bug 等级得分;S3为Bug 总数量得分;指标权重分别设定为0.3、0.5、0.2,权重之和为1。这里的权重设定标准是参考德尔菲法(专家共识),由测试团队内部专家根据自己的经验给出指标,然后取平均值,最后经过团队共同评审讨论确认。
2.3.3 性能、稳定性测试
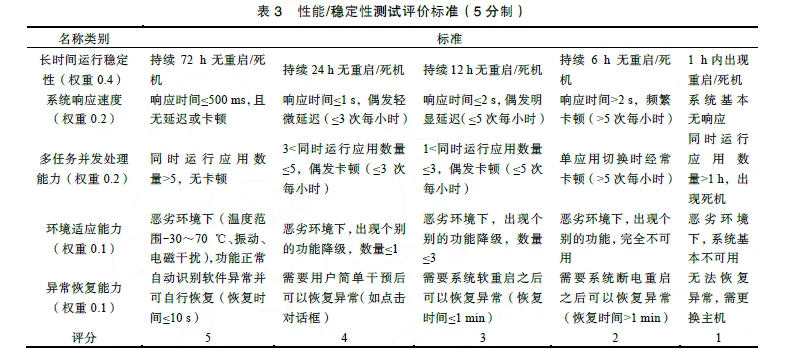
测试目标是确保多任务并发场景下的系统资源分配合理性,如中央处理器(Central ProcessingUnit, CPU)、内存、图形处理器(Graphics ProcessingUnit, GPU)等、人机交互响应时间和流畅度、系统在长时间运行下的稳定性(无死机、黑屏、重启等故障),主要参考标准是SAE J3069 [9]。性能/稳定性对用户的感知体验影响很大,重要度很高,也是需要投入较多资源的一项。核心测试方法包括:1)长时间持续运行(如72 h),循环执行典型的用车场景(如导航+音乐+语音交互+多屏互动),监控死机、重启、服务崩溃、内存泄漏、线程阻塞等关键问题;2)系统响应速度测试,包括触摸屏点击后的反应时间,播放各类视频的流畅度等;3)使用Monkey 压测(安卓系统)或SOA 服务压测(QNX 系统),模拟高负载场景,监控系统CPU/内存/GPU 占用率;4)故障注入,强制关闭某些关键进程,如控制器局域网络(Controller AreaNetwork, CAN)通信服务、面向服务的架构(Service-Oriented Architecture, SOA)通信服务,模拟实车的通信故障,监控系统是否会出现死机、黑屏。评分标准如表3 所示,对于细分功能点,性能、稳定性测试的综合测评得分计算方法为
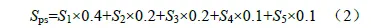
式中,S1 为长时间运行稳定性得分;S2 为系统响应速度得分;S3 为多任务并发能力得分;S4 为环境适应能力得分;S5 为异常恢复能力;指标权重分别设定为0.4、0.2、0.2、0.1、0.1,权重之和为1。权重设定标准也是参考德尔菲法(专家共识)。
2.3.4 用户体验测试
目标是通过用户的主观感知,对交互易用性、功能设计合理性、交互流畅度、情感化需求支持度等维度,进行主观评价。群体选取需要具有代表性,比如新手司机、老车主、儿童群体、特殊人群等,保证较广的覆盖面。YANG 等提出一种以声、光、热和人机交互数据为关键指标的主观评价方法[10]。本文采用的评价标准如表4 所示。

测试是在用户并不了解功能需求方案的前提下进行,避免专业测试过程中对于功能定义先入为主的思想。
2.3.5 兼容性测试
兼容性测试目标是保证软件和硬件的兼容性,比如可支持外接设备的正常使用(蓝牙电话、蓝牙耳机、USB、WIFI 连接等);安卓系统第三方应用的适配度(对标手机)。测试场景比较简单,但是资源投入并不小,以蓝牙电话为例,单个汽车品牌的用户群体,使用的手机型号就可能上千种,全面覆盖从测试经济性上是不合理的,可以通过选择主流品牌、不同的操作系统、不同的蓝牙协议版本、市场占有率高的手机型号做覆盖,评价标准如表5 所示。

2.3.6 安全性测试
安全性测试目标是保证座舱符合信息安全(参考标准SAE J3069[11])、功能安全(参考标准ISO26262[12])、GDPR 数据隐私(参考标准GDPR 通用数据保护条例[13])等安全性要求,防止车载网络被恶意攻击,保证关键功能(如仪表、泊车影像)符合功能安全指标,防止用户隐私数据泄漏。测试方法包括:1)车载网络渗透测试,比如伪造网络节点注入恶意CAN 总线报文(影响驾驶安全的车速信号、档位信号等),确保座舱可以通过内部加密的校验方式,如循环冗余校验(CyclicRedundancy Check, CRC),完全不受干扰;2)OTA升级安全测试,模拟服务器推送恶意篡改的升级包,确保座舱可以通过内部签名校验机制,拒绝升级非法升级包;3)关键功能安全等级测试,如仪表盘车速信息更新速度,通过冗余机制,如GPU冗余,在系统负载极高的情况下,仍然可以保证车速及时、准确的更新。评价标准如表6 所示,综合得分Ss计算方法为
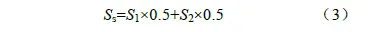
式中,S1 为信息安全得分;S2 为功能安全得分;指标权重分别设定为0.5、0.5,权重之和为1。权重设定标准也是参考德尔菲法(专家共识)。
2.3.7 自动化测试
自动化测试是提高效率的有效解决方案之一,如姜明远等提出的一种座舱自动化测试系统[14]。本文认为如何识别适合自动化执行的功能,是测试方案的重点。适合自动化的功能:1)功能逻辑清晰,如车辆控制开关;2)高优先级测试用例,使用频次很高;3)需要压力测试的场景,如操作系统的上下电循环,小概率严重问题复现。不适合自动化的功能:1)需要主观评价,如泊车影像的图像质量;2)低优先级测试用例,在回归测试中运行频次很低;3)开发阶段的不成熟功能,自动化执行失败率较高,还需要不断适配;4)预期结果不确定的功能,会影响自动化的判断。
2.4 模型评分计算方法
2.4.1 功能权重设置规则
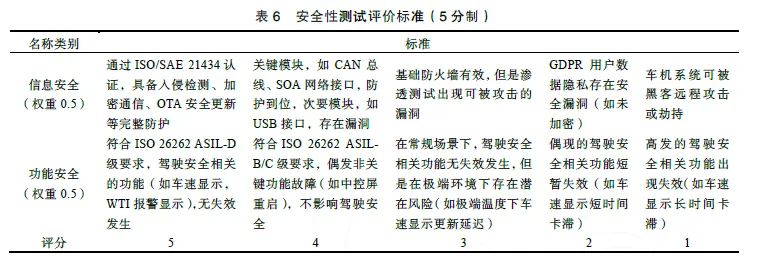
采用二维权重αij,其中一维权重αi 表示第i个功能模块的权重占比,二维权重αij表示第i 个功能模块的第j 个细分功能点的权重占比。对于一维权重,需满足所有功能模块的权重之和为1;对于二维权重,需满足在同一个功能模块下的所有细分功能点的权重之和为1。具体见式(4)和式(5)。权重越高,表明功能的重要度越高。
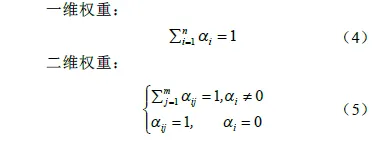
2.4.2 评价指标权重设置规则
采用一维权重βk,表示第k 个评价指标的权重,需要满足所有评价指标的权重之和为1。具体见式(6)。权重越高,表明评价指标的重要程度越高。
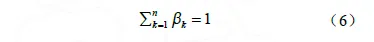
2.4.3 数据处理
细分功能点结合评价指标进行评估,不相关的指标权重βk直接设为0 即可。整个评价体系统一采用5 分制标准。

3 模型应用案例
选取一款市场上近3 个月销量保持在TOP10车型的智能座舱作为测评对象,验证模型的有效性。主流智能座舱在高智能化程度、硬件架构、人机交互方式、生态系统整合等方面呈现出显著的技术趋同性和差异化创新的核心特点。按照模型中的功能体系和测评体系,对功能点进行全面测评,结合专业客观测试和用户招募主观测试,对所有细分功能点进行5 分制打分,代入模型后得出整体评分,如表7 所示。

该座舱样本总体加权得分为4.2 分,属于比较高水平的综合表现,说明软件质量和成熟度都比较高,下面展开做一些分析。座舱控制模块,简单易用、界面友好、稳定性高,评测中没有出现任何的失效故障,在快速切换页面的情况下有偶发不跟手的轻微性能问题,总评分为4.2 分,表现较好。
视觉模块,泊车影像清晰度、环视拼接都达到比较高的水平;DMS 监测能够准确捕获驾驶员的疲劳、分心,而且基本没有误报以及频繁的打扰。总评分为4.1 分,表现较好。
智能辅助驾驶交互模块,环境感知物的显示布局比较合理;出现车道偏离时的预警提示准确,界面清晰易懂。总评分为4.1 分,表现较好。
娱乐和导航模块,在线音乐总体使用体验不错,但是存在偶发的播放卡顿;导航的使用过程比较流畅,准确性也可以;蓝牙电话的基础能力不错,连接成功率、连接质量都比较好,但是在某款主流手机的连接测试中,出现偶发受外部信号干扰的情况。总评分为3.8 分,有一些提升空间。
语音模块,出现偶发首次唤醒成功率不够高的问题,二次唤醒可以成功;语音控制中,语音识别、语意理解都比较准确,指令也能准确下发执行。基于AI 的查询能力也不错。总评分为3.9分,表现可以。系统级应用模块,测评表现很稳定,总分达4.6 分,说明系统稳定性较高,框架设计较合理,能够为座舱提供有力的支撑。
4 结语
智能座舱覆盖的功能范围很庞大,用户使用率很高,体验感知度很高,制定合理的测试方案和测评模型很关键。测评工作需要依赖大量的软件测试领域理论知识、经验以及测试管理方法,软件测试是质量管控的重要一环,但也如《Google软件测试之道》书中所述,软件质量保证绝不仅是测试的职责,而是整个软件团队的职责,软件的Bug 应该尽早扼杀在代码研发阶段,而不是让测试团队来兜底[15],对测试行业具有重要的指导价值。
智能座舱仍然处于高速发展阶段,技术创新不断迭代,测评方法也需要不断更新,与传统汽车电子领域的区别较大。本文从智能座舱的功能模块和细分功能点切入,设计了一种测评模型,对测试方法做了详细介绍,最后通过实例验证了测评模型的有效性。希望对汽车软件、特别是智能座舱领域,有一定的参考价值。
-

Digi-Key KOL 系列:商务车型的影音娱乐系统应用方案
-

由内到外的智能网联车:车联网现状及发展
-

labview2016
-

直播回放: TI DLP® 技术在汽车上的创新及全新应用
-

回放 : TI mmWave 毫米波雷达在汽车车内的应用
-

Amplifier Protection Series
-
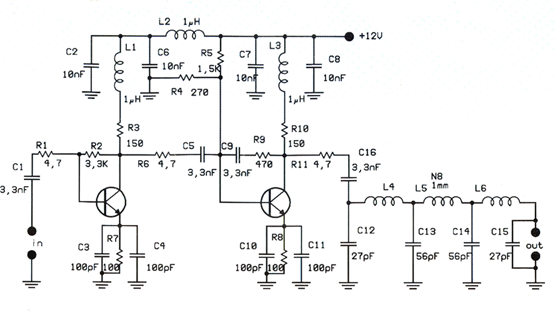
1瓦线性调频增强器
-
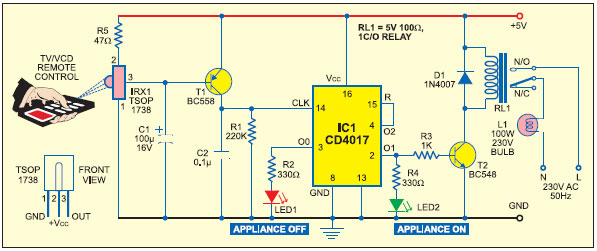
家用电器遥控器
-

12V 转 28V DC-DC 变换器(基于 LM2585)
-
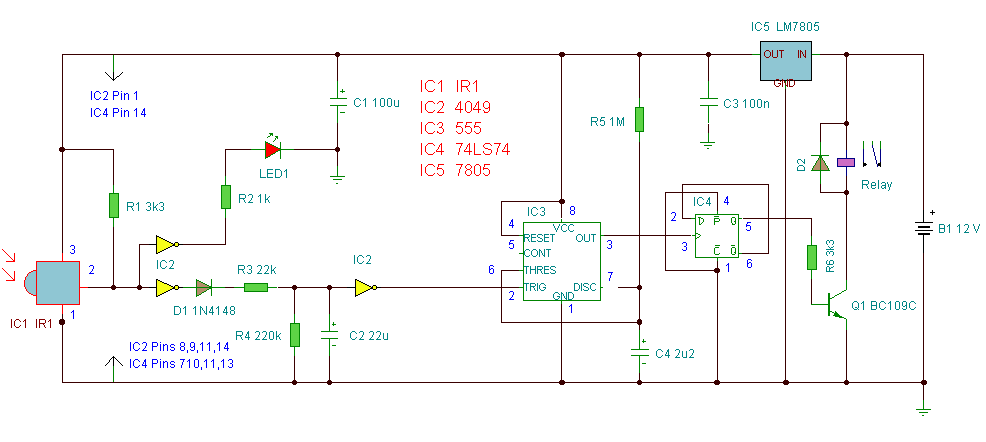
红外开关
-
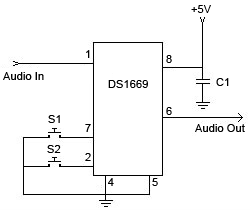
DS1669数字电位器
-
HA1377 桥式放大器 BCL 电容 17W(汽车音频)