



Transformer如何让自动驾驶变得更聪明?
2025-11-16 来源:智驾最前沿
自动驾驶中常提的Transformer本质上是一种神经网络结构,最早在自然语言处理里火起来。与卷积神经网络(CNN)或循环神经网络(RNN)不同,Transformer能够自动审视所有输入信息,并动态判断哪些部分更为关键,同时可以将这些重要信息有效地关联起来。
这种能力对自动驾驶来说至关重要。由于驾驶场景复杂多变,自动驾驶系统需要同时处理来自摄像头、毫米波雷达、激光雷达和高精地图等多种来源的数据,还要理解车辆、行人等参与者之间随时间的动态交互。传统方法在应对这种多模态、长时序的信息关联时会感觉力不从心,而Transformer的架构特性刚好弥补了这些短板。

图片源自:网络
Transformer能将“前方100米处一个模糊的物体”、“旁边车道一辆正在减速的汽车”以及“几秒钟前路口突然出现的行人”这些看似独立的信息碎片,整合成一套统一的“输入单元”。它会自动在这些单元之间建立有用的联系,最终提炼出对当前驾驶决策最有价值的核心信息。这种强大的全局关联能力,让感知、预测和规划这些原本界限分明的模块,可以用一种更集成、更智能的方式协同工作。
Transformer的核心机制:自注意力和多头注意力
Transformer之所以强大,其关键在于“自注意力”机制。自注意力机制会将输入的每一个元素(比如图像的一块patch、激光雷达的一个点)转化为Query(查询)、Key(键)、Value(值)这三种不同的向量:
查询:可以理解为当前元素提出的问题:“我应该关注谁?”
键:是其他元素提供的标识:“我是谁?”
值:是其他元素所包含的实际信息:“我有什么内容。”
查询会和所有键做相似度比较,得到权重,再把这些权重作用到所有值上,最终得到这个位置的新表示。这个过程就是让模型自己决定“我应该关注哪些其他位置的信息来更新当前位置的理解”。为了稳定训练过程,注意力计算会通过一个缩放因子进行调整。
Transformer不会只做一次注意力计算,而是采用“多头注意力”,即可以同时进行多组独立的注意力运算。这好比让多个专家从不同角度分析同一段信息,有的专家专注于局部细节,有的专家则善于把握全局关系,他们最后会将见解综合起来,形成更全面、更深刻的理解。

图片源自:网络
对于自动驾驶中常见的时间序列问题,Transformer可以轻松地将过去若干帧的数据作为输入序列,通过注意力机制直接学习不同时刻之间的依赖关系。再辅以“位置编码”来告知模型各个输入单元的先后顺序,从而有效地预测出车辆、行人未来的运动轨迹。

Transformer对感知的好处
之前,感知里最常见的做法是用卷积网络做图像特征提取,再用专门的检测头(如Faster R-CNN、YOLO)做目标检测。Transformer做的就是把检测问题重新表述成了“一组查询去匹配场景里的物体”,这类方法(比如DETR、以及后续变体)减少了很多手工设计的锚框、NMS(非极大值抑制)等步骤,思路上更直接,也更统一。
1)长距离与稀疏目标的检测更鲁棒
得益于全局注意力,Transformer在分析一个远处的小目标时,能够同时参考近处的大物体和整体的场景上下文。这在目标被部分遮挡或图像分辨率有限的情况下尤其有用,模型可以依据其他相关线索推断出“那可能是一个行人”或“远处有一辆停靠的车辆”。
2)多模态融合更自然
自动驾驶车辆装备了如摄像头、毫米波雷达和激光雷达等传感器,Transformer则提供了一个统一的框架,可以将这些不同来源的数据都表示为“输入单元”,然后通过跨模态注意力机制让它们自由地交流信息。举个例子,激光雷达提供的精确三维点云信息可以与摄像头丰富的纹理、颜色信息相互补充,模型能自动学习在何时、以何种方式信赖哪一种传感器,实现真正意义上的早期融合。

图片源自:网络
3)端到端的检测与跟踪更容易结合
Transformer可以把检测框、历史轨迹、甚至ID信息都当作token,让模型同时做检测和关联,能减少后处理步骤,降低误关联(ID-switch)的概率。Transformer在多目标跟踪(MOT)领域的进展,可以有效解决自动驾驶里连续帧中物体身份保持的问题。

Transformer如何让决策更有洞察力
预测其他道路参与者的未来轨迹,并规划出自车的安全路径,是自动驾驶的核心任务,为实现这一目标,需要模型具备强大的推理能力,能够理解参与者之间复杂的时空交互。Transformer的自注意力机制在这里再次展现出巨大优势。
1)更好地建模交互行为
传统方法在建模多智能体交互时会显得比较僵硬。而Transformer的注意力机制天生就能计算任意两个参与者之间的影响程度,并能动态地将注意力聚焦在“关键参与者”上。如在通过一个无信号灯的路口时,Transformer能同时考虑左侧来车、右侧准备横穿的行人以及前方车辆的意图,从而生成多种合理的未来概率分布,以便自动驾驶汽车可以安全、高效地驾驶。
2)长时记忆更友好
某些驾驶行为的预测需要回顾较长的历史信息。要预测一个行为,有时候需要回看很长时间的过去状态(比如某辆车的转向灯在几秒前就亮了,但始终慢速行驶,现在终于开始并线)。Transformer对长序列的处理比传统LSTM等要更为稳健,而且可以并行计算,训练效率会更高。当然,为了处理更长的历史信息,需采用稀疏注意力、局部—全局混合机制或缓存机制来控制计算量。
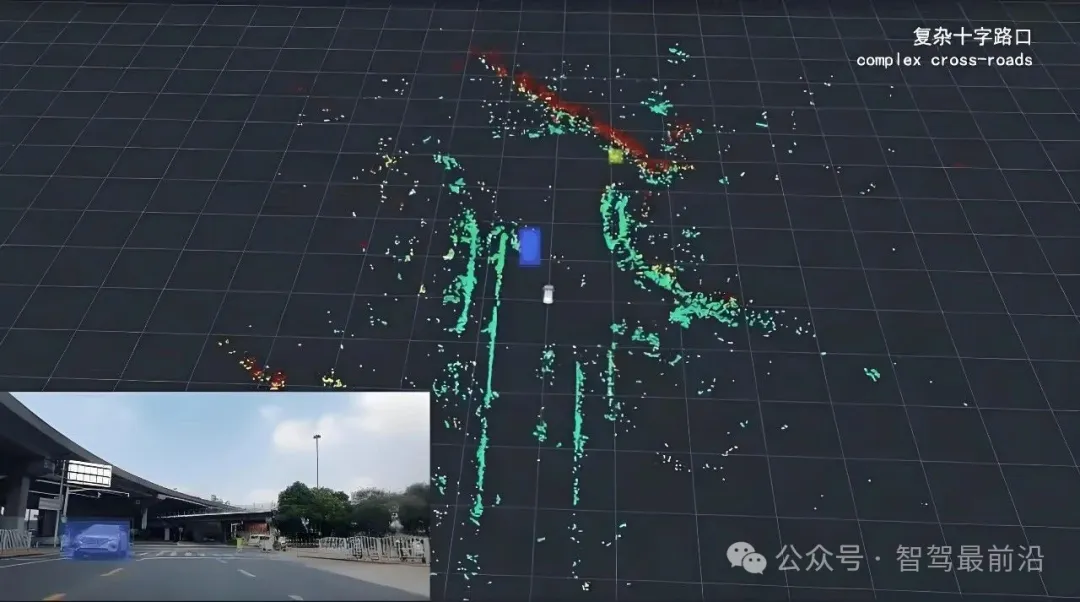
图片源自:网络
3)规划可以直接利用预测注意力
当预测模块和规划模块都基于Transformer构建时,它们之间的信息流动会更加顺畅。规划模块不仅能看到预测模块输出的轨迹,甚至能“看到”预测过程中的注意力分布,即其他交通参与者最关心谁。这为自车的决策提供了更深层次的上下文,如在通过一个拥挤路口时,自动驾驶汽车可以对那个注意力高度分散、行为不确定的车辆保持更大的安全距离。

最后的话
Transformer为自动驾驶带来了一种更强大、更灵活的“信息关联与理解”的新范式。它让机器能够像人类一样,更全面地审视复杂的驾驶环境,将不同来源、不同时间的信息融会贯通,从而做出更前瞻、更合理的决策。
-

Digi-Key KOL 系列:商务车型的影音娱乐系统应用方案
-

由内到外的智能网联车:车联网现状及发展
-

labview2016
-

直播回放: TI DLP® 技术在汽车上的创新及全新应用
-

回放 : TI mmWave 毫米波雷达在汽车车内的应用
-

Amplifier Protection Series
-
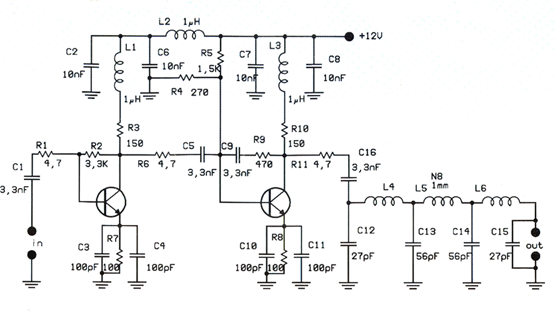
1瓦线性调频增强器
-
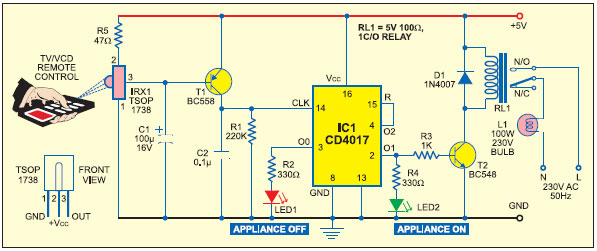
家用电器遥控器
-

12V 转 28V DC-DC 变换器(基于 LM2585)
-
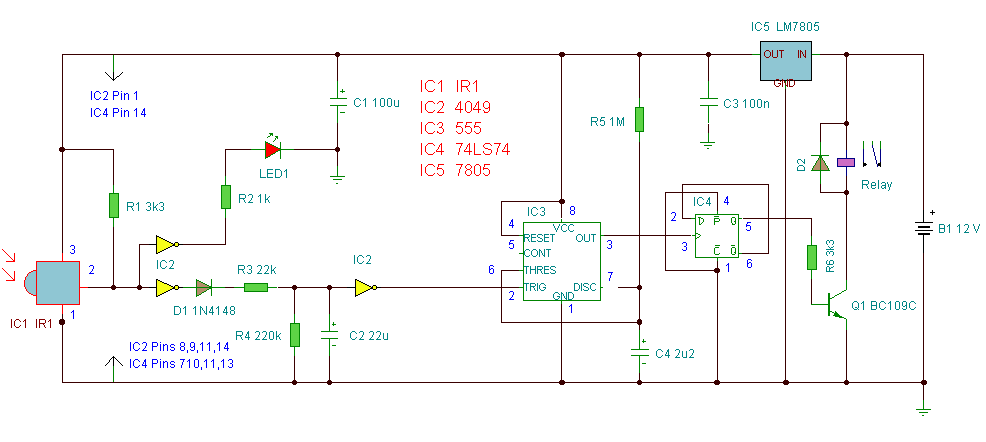
红外开关
-
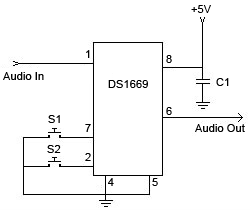
DS1669数字电位器
-
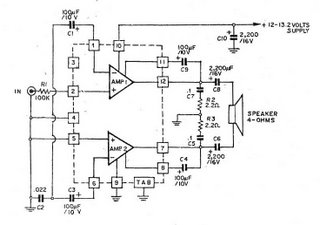
HA1377 桥式放大器 BCL 电容 17W(汽车音频)