



从控制到系统:TI利用边缘AI重塑嵌入式MCU的边界
2026-03-24 来源:EEWORLD
在嵌入式世界里,微控制器很重要,却常常被忽视,以至于很少出现在任何技术浪潮的宏大讨论中。但正是这些数以千万计的芯片,支撑着工业系统的稳定运行、家电设备的日常响应,以及无数传感器与执行器之间的基本逻辑。
即便是AI来临时,MCU也只负责确定性控制,把复杂计算和智能留给了应用处理器及云端,这种分层不仅清晰,而且更加的经济高效。
如今,这种稳定正在被打破。
以Agent AI为代表,证明边缘端也可以有一定的AI能力,这时既不需要也不能够把所有AI能力都交给云端。同样,对于更边缘的产品而言,AI能力也变得重要,比如语音唤醒不能等待网络返回,工业异常检测不能依赖远程决策,可穿戴设备更无法承受持续的数据上传。
德州仪器(TI)将边缘AI趋势归结为四个维度:响应速度、功耗、隐私与可靠性。这些因素最终指向同一个方向,计算必须回到数据诞生的地方。
MCU能否承载AI?
当计算位置发生变化,MCU的角色也被迫改变。它不再只是执行预设逻辑,而开始面对原始数据,这意味着它需要具备一定的理解能力。
但问题在于,MCU是否承载得起AI?
长期以来,答案是否定的。MCU的资源约束决定了它难以运行复杂模型,而一旦引入AI计算,又会直接影响实时控制的确定性。
也正因为如此,边缘AI在过去几年主要停留在高性能处理器、SoC或者至少是高端MCU上,比如最起码也要意法的STMN6,或者英飞凌PSoC Edge等MCU中,这些MCU的性能甚至达到了SoC的水平,以至于被视为正在跨界SoC的产品。
但是,并不一定所有AI MCU都需要更高级的处理器以及更大的存储空间,比如TI选择了一条更具挑战性的路径:不是让MCU变成处理器,而是让AI适应MCU。
让AI与控制并行存在
德州仪器 MSP 微控制器产品线经理罗一丁提出了一句高度概括性的判断:“AI不应该只存在于云端,而应该无处不在地运行在每一个嵌入式设备中。”AI的普适性给了MCU更多的发展空间。
但是也如德州仪器 ASM 微控制器工业业务负责人吴健鸿所述:“如果用CPU去跑AI模型,它就无法同时做好电机控制。”
也就是说MCU很难承载AI的根本原因——资源冲突。
TI的解决方式,是在MCU内部引入TinyEngine NPU,并通过硬件层面的任务划分,让两种本质不同的计算同时存在:
CPU负责实时控制,NPU负责AI推理
吴健鸿给出了清晰的总结:“我们加入NPU的核心原因,就是为了让AI运算和实时控制可以并行,而不是互相干扰。”
这并不是一次简单的性能升级,而是一次架构上的解耦。它让中低性能的MCU第一次可以在不破坏确定性及低延迟的前提下,引入非确定性的智能计算。

TinyEngine NPU非常适配功耗、成本均受限的AI场景中
TinyEngine NPU 核心优势

根据TI的官方阐述,TinyEngine NPU 突破了长期以来制约嵌入式人工智能广泛普及的关键设计瓶颈,具备以下优势:
1.相较于纯软件实现的人工智能方案,单次推理能耗降低至 1/120,延迟降低至 1/90
2.算力达 2.56 GOPS,可支撑深度学习模型的实时边缘 AI 推理。
3.支持 8 比特、4 比特、2 比特量化及混合精度配置,支持原位运算,有效解决存储容量受限问题。
4.兼容多种神经网络层类型,包括卷积层(常规卷积、深度卷积、逐点卷积、转置卷积)、全连接层、池化层(平均池化、最大池化),并支持批归一化。
5.简化工具链降低开发复杂度,开发周期从数周缩短至数小时。
可以看出,TinyEngine并不试图对标高端SoC,但它的目标更明确——在超低功耗和低成本下,完成足够好的AI推理。


比如在TI的一个演示中,使用Arm CPU处理手写识别模型时延达到了91ms,而使用NPU时,处理速度仅为6ms,提升了15倍之多。
一美元的AI:边缘AI的分水岭
TI正在把AI能力推向更低成本区间。
MSPM0G5187的定价颇具象征意义。这颗基于Cortex-M0+的MCU,在集成2.56 GOPS NPU的同时,将价格压低至1美元以内,使AI第一次进入大规模成本敏感市场。

MSPM0G5187产品框图
罗一丁在发布中提到:“很多边缘AI应用过去无法落地,并不是没有需求,而是受限于功耗、成本和尺寸。”
当这些约束被打破时,AI可以以更低成本进入此前的智能设备中。例如在MSPM0G5187的AI示例展示中,可应用于包括智能家居设备中的唤醒词检测、可穿戴健康监测设备中的手势与活动监测甚至工业电机中的电机振动检测等等,这些AI应用不再依赖云端,而是在本地完成。
这种变化的关键不在于更强,而在于更普及。
从执行控制到参与决策
相比MSPM0系列在低功耗场景中的扩展,AM13Ex系列则体现了另一种方向:AI正在深入控制系统内部。
AM13Ex的重点不止是NPU,而是NPU真正结合了实时控制能力。实际上,此前TI已经在C2000中集成了NPU。如今,在TI Arm实时控制MCU体系中,也同样集成了NPU,使得产品体系更为广泛。
无论是20多年间的C2000系列,还是TI如今的Arm实时控制产品线,始终围绕一个核心目标展开:如何在复杂系统中保持确定性与高精度控制。而AI的加入,并不是替代这一体系,而是增强它。

AM13Ex产品框图,以及应用于洗衣机中的示例
吴健鸿举例道:“在光伏系统的电弧检测中,传统方法大约85%的准确率,而通过TI的NPU,AI可以将准确率提升到超过99%。”
这种提升并不仅仅意味着更好,而是在很多场景中意味着从不可用变为可用。例如在电机的轴承的故障检测、洗衣机负载平衡、电池健康检测、风机负载失衡检测,空调系统优化,控制算法优化等等更多功能。

NPU在电机控制中的应用举例
更关键的是,这一切并没有打破原有控制架构。吴健鸿特别强调:“CPU还是专注做控制,NPU去做判断,两者是分工协作的关系。”
在这种架构下,MCU不再只是执行控制算法,而是开始参与决策过程本身。这标志着其角色从控制器向系统节点的转变。
值得一提的是,在电机控制领域,TI提供了两大选择,既有传统的C2000产品线,同时也有基于Arm的产品线。“客户已经在Arm生态中积累了大量代码,我们必须让他们在不改变体系的前提下,也能用上C2000的各种实时控制与外设的能力。”吴健鸿说道。
MCU竞争正在发生转移
当MCU开始具备AI能力,其竞争维度也随之改变。但竞争已经不再局限于参数或价格,而是延伸到系统能力与开发效率。与此同时,SoC厂商与新兴AI芯片公司也在向下渗透,试图以更强算力覆盖MCU场景。
在这样的多重竞争中,TI的策略并不是单点突破,而是构建完整的系统AI能力,包括C7 NPU(已应用于TDA54-Q1 与 TDA4VEQ1 SoC中),以及TinyEngine。另外值得一提的是,TI更是从模拟信号链到控制,再到AI推理,其能力覆盖了一整条技术路径。
TI始终强调其从传感到AI的整体能力,这种整合,使MCU不再是孤立器件,而成为系统架构中的关键节点。
罗一丁强调,在边缘 AI 领域,大家很容易陷入单纯的跑分竞赛,但真正的商业落地看重的是综合效能——如何提供更好的算力与能耗比,而非单纯依赖云端 AI。
AI需要可扩展性
为了迎接边缘AI万物时代的到来,产品需要考虑演进与扩展。工程师们不愿花费数月时间基于某款微处理器开发解决方案,却在产品升级至更高性能处理器时不得不从头再来。也正因此,芯片厂商需要打造在功能、性能和成本上均具备可扩展性的产品系列。这一思路有助于确保其各类人工智能嵌入式处理器之间实现无缝迁移,让开发者能够尽可能简便地在不同器件间复用已有开发成果。边缘AI同样遵循这一规律。例如,设计家用机器人的开发者可能希望同时推出两款产品:一款配备三个摄像头、具备环视视觉功能的高端版本,以及一款仅搭载单个前置摄像头的入门级版本。
具备可扩展性的边缘 AI 加速器件产品系列,能够支持软件从高端机型移植到入门级机型,最大限度减少两款产品的开发资源投入。可扩展性还能让开发者在产品迭代过程中,将研发投入从一个平台延续至下一个平台。
TinyEngine NPU就是一个最好的例子。
正如上文所述,搭载 TinyEngine NPU 的德州仪器微控制器目前包括以下三款已发布的产品。
TMS320F28P550SJ该芯片属于 C2000 系列 TMS320F28P55x 微控制器,其内置 NPU 可分担主 CPU 的 AI 推理任务。
AM13E230x该系列基于 Arm CortexM33 内核,通过集成 NPU 与先进实时控制架构,在家电、机器人及工业系统中实现自适应控制与预测性维护。
MSPM0G5187该系列为 80MHz Arm CortexM0+ 内核微控制器,隶属于 TI MSPM0 产品家族,借助 NPU 在高性价比、低功耗电子设备中实现边缘 AI 能力。
另外,TI还开发了C7 NPU,这是一款高性能、低功耗的人工智能加速器,集成于 TDA54-Q1 与 TDA4VEQ1 系统级芯片(SoC)中,以满足视觉类应用的算力需求。

软件成为关键开发体验
除了硬件架构,软件正在成为另一个决定性因素。
罗一丁表示,开发者对工具链的重视程度往往超乎硬件本身。TI 提供的工具能让传统的嵌入式工程师在几天内跑通 AI 模型,而不是几周,这种易用性是TI的核心软实力。
吴健鸿表示,目前TI提供了两套IDE,一是传统的 CCStudio 集成开发环境,内置 TI 专属编译器,同时增加 AI 辅助功能,大幅降低软件开发门槛。二是 CCStudio Edge AI Studio,这款工具面向客户免费开放,覆盖 AI 设计全流程——不仅可快速搭建适配模型,还能完成数据采集、神经网络选型与优化、模型训练及跨 MCU 部署等工作。
目前,TI的Edge AI Studio提供了已提供超过 60 种模型和应用示例,工程师可直接导入评估。

如图所示,Edge AI Studio支持各类分类、检测、时序等等AI应用。
TI的CCS开始支持生成式AI
随着大语言模型的普及,vibe coding正在扩展至各类编程工具中,嵌入式同样如此。在2026 Embedded World上,德州仪器展示了CCStudio生态系统中集成的生成式 AI,通过集成 Claude Code 接口,设计人员能结合 TI 丰富的示例库加快代码开发与系统配置。
罗一丁提到:“工程师可以用自然语言生成代码,在几分钟内完成部署。”这不仅降低了门槛,也在改变嵌入式开发逻辑本身。

TI已经展示了一系列利用生成式AI加速嵌入式开发的示例。

如图所示,CCS接入了Claude Code,自然语言描述如下:我拥有一块MSPM0G3507 LaunchPad开发板和一块BOOSTXL-EDUMKII扩展板。请利用L-C 摇杆与按键实现一个打砖块游戏,并使用蜂鸣器播放音效。游戏开始前,需加入摇杆校准步骤。
用户输入这些自然语言之后,CCS便会自动进行执行系统配置,代码编写等等功能。
罗一丁说道:“未来会看到更多的工程师利用 AI 的代码生成功能,实现研发周期的缩短,我非常鼓励大家自己去下载并尝试这些AI强大的功能。”
MCU重新成为系统的核心节点
从更宏观的角度来看,MCU当然并没有被AI时代淘汰,反而因为AI的引入获得了新的生命力。只是这种变化,不再体现在单一性能指标上,而体现在其在系统中的位置变化。
它正在成为最靠近物理世界的数据处理与决策节点。
这也解释了为什么像TI这样的公司,既有TDA5这样更强大1200 TOPS算力的处理器,同时也有集成MOPS或者GOPS算力的MCU。
正如吴健鸿在谈到MCU在人形机器人应用时所指出的:“如果所有数据都回到大脑再做决策,就一定会有延迟。”
这句话实际上给出了边缘AI最本质的逻辑:AI必须以分布式存在。而MCU,正是这种分布式智能中最基础、也最关键的节点。
当系统复杂度不断提升时,那些在底层稳定运行的组件,则会成为决定系统下限的关键。
MCU不会消失,但它正在完成一次角色转变——从单纯的执行走向AI系统的边缘。
1978 年 TI 发明了数字信号处理技术,为未来的人工智能发展铺平了道路。四十年过去,如今的这场变化,也才刚刚开始。
上一篇:六大全新产品系列推出,MCX A微控制器家族迎来创新
下一篇:暂无
- 意法半导体中国本地造STM32微控制器启动规模量产
- 意法半导体发布Stellar P3E 汽车MCU内置AI加速
- 德州仪器 (TI) 扩展微控制器产品组合及软件生态系统,助力边缘 AI 在各种器件中落地
- 3D打印“狂飙”背后:兆易创新GD32 MCU多元方案驱动性能升级
- 基于恩智浦MCU的人形机器人灵巧手解决方案
- 国民技术发布N32H49x系列MCU:以澎湃性能与全链路可靠赋能工业控制、储能与光通信
- 英飞凌推出基于PSOC™ Control C3微控制器的ModusToolbox™电源套件
- 让AI为你优化代码,提升MCX MCU程序开发效率!攻略在此~
- 六大全新产品系列推出,MCX A微控制器家族迎来创新
- 英飞凌强化车规级微控制器产品组合:符合ISO/SAE 21434标准、获中汽研认证
- 六大全新产品系列推出,MCX A微控制器家族迎来创新
- 意法半导体全新STM32C5系列,重新定义入门级微控制器性能与价值,赋能万千智能设备
- 模组复用与整机重测在SRRC、CCC、CTA/NAL认证中的实践操作指南
- 有源晶振与无源晶振的六大区别详解
- 英飞凌持续巩固全球微控制器市场领导地位
- 使用 Keil Studio for Visual Studio Code开发 STM32 设备
- 从控制到系统:TI利用边缘AI重塑嵌入式MCU的边界
- 蓝牙信道探测技术原理与开发套件实践
- Microchip 推出生产就绪型全栈边缘 AI 解决方案,赋能MCU和MPU实现 智能实时决策
- LoRa、LoRaWAN、NB-IoT与4G DTU技术对比及工业无线方案选型分析
-

【TI MSPM0 应用实战】智能小车+工业角度编码器+血氧仪+烟雾探测器!硬核参考设计详解!
-

2022 Digi-Key KOL 系列: 你见过1GHz主频的单片机吗?Teensy 4.1开发板介绍
-

TI 新一代 C2000™ 微控制器:全方位助力伺服及马达驱动应用
-

MSP430电容触摸技术 - 防水Demo演示
-

直播回放: Microchip Timberwolf™ 音频处理器在线研讨会
-

基于灵动MM32W0系列MCU的指夹血氧仪控制及OTA升级应用方案分享
-
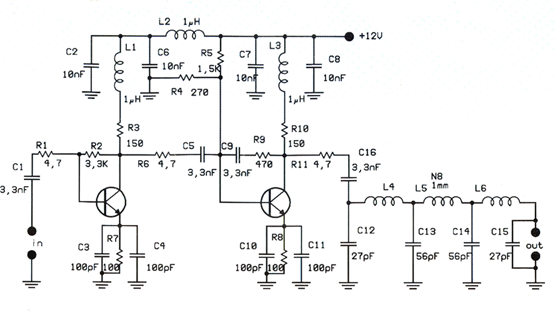
1瓦线性调频增强器
-
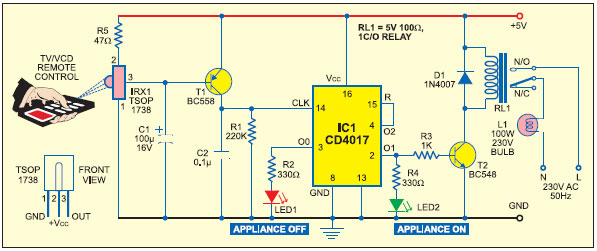
家用电器遥控器
-

12V 转 28V DC-DC 变换器(基于 LM2585)
-
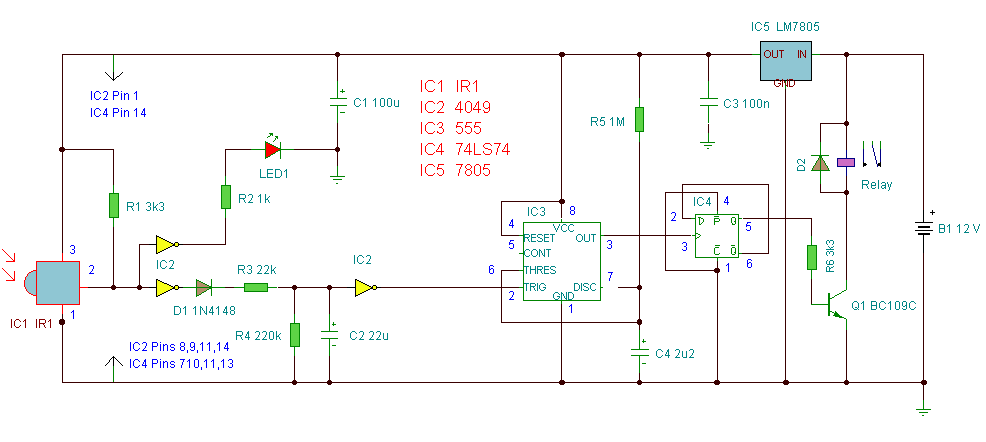
红外开关
-
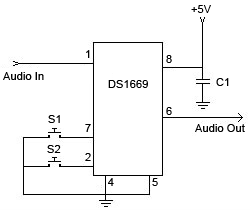
DS1669数字电位器
-
HA1377 桥式放大器 BCL 电容 17W(汽车音频)