



基于大模型的汽车座舱视觉感知技术的研究应用
2026-02-02 来源:智能汽车设计
摘 要: 随着汽车智能化进程的加速推进,汽车座舱的功能已从单纯的驾驶空间转变为集多种智能交互于一体的智能座舱。其中,视觉感知技术作为智能座舱的核心组成部分,对保障驾驶安全、提升用户体验具有关键作用。文章聚焦于基于大模型的汽车座舱视觉感知技术,针对复杂驾驶环境下驾驶员疲劳与分心状态检测、乘客分布识别以及视线估计等难题展开深入研究。通过采用数据归一化处理、多线索与多尺度信息融合、时序信息引入、域自适应及注视区域预测等关键技术,构建了一套高精度、高鲁棒性的视觉感知系统。该系统能够实时监测驾驶员状态,识别车内乘客分布,并提供安全提醒与个性化服务,显著提升了驾驶安全性和乘客体验。
随着汽车智能化的快速发展,汽车座舱不再仅仅是一个驾驶空间,更是集成了多种智能交互功能的智能座舱[1]。视觉感知作为智能座舱的关键技术之一,对于保障驾驶安全、提升用户体验具有极其重要的意义。其中,视线感知技术能够实时监测驾驶员和乘客的视线状态,从而为安全驾驶和个性化服务提供有力支持[2]。然而,在实际的驾驶环境中,视觉感知面临着如复杂光照条件、头部运动、不同相机参数等诸多挑战,这些都给准确的视线估计带来了困难。因此,深入研究基于大模型的汽车座舱视觉感知技术具有重要的现实意义。
在汽车智能化浪潮的推动下,汽车座舱正经历着前所未有的变革。传统的驾驶空间逐渐演变为集成了导航、娱乐、信息显示等多种功能的智能座舱[3]。视觉感知技术作为智能座舱的“眼睛”,承担着获取车内环境信息、理解用户意图的重要任务。特别是在复杂驾驶环境中,精准检测驾驶员的疲劳、分心状态以及识别车内乘客分布状态,对于保障行车安全至关重要[4]。然而,实际驾驶场景中存在的复杂光照条件、头部运动、不同相机参数等因素,给视觉感知带来了巨大挑战[5]。因此,开展基于大模型的汽车座舱视觉感知技术研究,具有重要的理论意义和现实价值。
1 技术背景
1.1 汽车座舱视觉感知的重要性
汽车座舱作为人机交互的主要场所,其视觉感知能力直接影响着驾驶安全和用户体验。通过视觉感知技术,可以实现对驾驶员状态的实时监测,及时发现疲劳驾驶、分心驾驶等危险行为,从而采取相应措施保障行车安全。同时,对车内乘客分布的准确识别,有助于提供个性化的服务,如自动调节座椅位置、空调温度等,提升乘坐舒适度。
1.2 现有技术面临的挑战
尽管近年来计算机视觉技术取得了显著进展,但在汽车座舱这一特殊场景下,仍面临诸多挑战。一方面,复杂光照条件(如强光直射、夜间低光照)会导致图像质量下降,影响特征提取的准确性;另一方面,驾驶员的头部运动、不同相机焦距以及个体差异等因素,增加了视线估计的难度。此外,车内环境的多样性(如内饰颜色、材质)也对模型的泛化能力提出了更高要求。
根据研究,现有技术在大模型部署方面存在硬件、软件、算力等问题,同时面临数据安全与隐私保护问题,以及训练数据在多样性、标注准确性、合规性等方面的难题。这些挑战使得汽车座舱视觉感知技术的实际应用仍处于发展阶段,需要进一步研究和改进。
2 技术方案
研究提出一种基于大模型的汽车座舱视觉感知技术方案,旨在通过大规模训练样本构建人眼图像与屏幕视线落点之间的映射模型,实现对新采集人眼图像的视线方向精准预测。该方案以人脸区域为输入,采用注意力增强机制聚焦眼部特征,并依托深度学习框架实现端到端的视线方向预测,整体技术方案如图1 所示,基于红外摄像头捕获驾驶员图像,通过关键步骤实现智能座舱环境下的驾驶员注视区域精准感知。

图1 视觉感知技术方案
该技术方案融合先进的图像处理技术、深度学习视线估计算法、3D 建模及空间计算技术,精确捕捉并分析驾驶员视线落点,为智能座舱营造更自然流畅的人机交互体验,并构建更加安全的驾驶环境,提供不可或缺的感知支撑。为实现视觉感知技术应用,为进一步提升模型性能,系统性地整合了如表1所述的关键技术:数据归一化处理、多线索与多尺度信息融合、时序信息引入、域自适应技术,形成具有高鲁棒性和强泛化能力的完整解决方案。
表1 视觉感知系统关键技术组成

为了克服轻微头部运动、不同相机焦距以及光照变化等因素对视线估计的影响,对相机拍摄得到的人脸面部区域图像进行归一化处理。归一化处理显著增强了神经网络模型的鲁棒性,使其能灵活应对多样化的图像数据,进而提升视线方向估计的精确度。具体归一化流程如图2 所示,包括建立三维坐标系、旋转校正、尺度变换和虚拟相机成像四个步骤。

图2 数据归一化处理流程示意图
(1)建立三维坐标系:以相机光心为原点,建立三维直角坐标系,其中X 轴方向为相机水平向右,Y 轴方向为相机竖直向下,Z轴方向为相机光轴指向。将图像中的像素点映射到该三维坐标系下,为后续处理提供统一空间基准。在映射过程中,需要利用相机的内参矩阵(包括焦距、主点坐标等)将二维图像坐标转换为三维相机坐标系下的坐标。这一步是基于相机标定的结果实现的,确保像素点在三维空间中的精确定位。
(2)旋转校正:通过旋转操作,使眼睛中心位于旋转后的相机坐标系的Z 轴上。这样可以消除由于头部倾斜等原因导致的眼睛位置变化,使后续的处理更加方便和准确。旋转操作涉及计算眼睛中心在三维坐标系的确切位置,并借助旋转矩阵精准调整图像至适当角度。旋转矩阵可以通过计算眼睛中心与Z 轴之间的夹角来确定,确保旋转后的图像中眼睛中心与Z 轴对齐。
(3)尺度变换:针对不同相机拍摄距离的差异,采用尺度变换方法进行调整。通过将图像缩放到统一的尺度,可以解决因拍摄距离不同而导致的人脸大小不一致的问题。尺度变换依据人脸区域尺寸(例如眼睛间距)的精确计算来确定合适的缩放比例。人脸区域被缩放至预设的标准尺寸(例如,固定两眼间距),以此确保不同拍摄距离下的人脸图像均保持一致的尺度。
(4)虚拟相机成像:利用虚拟相机成像技术,克服不同相机焦距不同带来的问题。通过模拟一个具有固定焦距的虚拟相机,将实际拍摄的图像转换为在该虚拟相机下的视角,从而使不同相机拍摄的图像具有一致性。虚拟相机成像需依据实际相机的焦距和内参矩阵,计算出图像至虚拟相机的投影映射关系。此过程借助重投影变换实现,旨在保证各焦距相机所摄图像在虚拟相机视角下视角一致,成像效果统一。
2.2 多线索和多尺度信息技术
眼部关键点信息对视线具有很大指导意义,引入眼睑关键点和瞳孔中心点信息约束模型训练,具体如图3 所示,除了预测视线的方向外,网络模型还同时预测眼部关键点信息,如眼睑和瞳孔中心点。利用关键点信息约束,有助于模型更准确地捕捉眼部特征,从而提高视线估计的准确性,提升模型效果。该模型以单张眼部图像为输入,通过卷积神经网络(CNN)自动提取图像中的边缘、纹理等关键特征[6],为后续任务奠定基础;随后将提取的特征输入全连接层(FC)进行深度整合与处理,其输出被分解为系数、平移和尺度三类参数,并传递至解码器(Decoder);解码器结合头部姿态信息,利用上述参数同步预测眼部关键点位置(如眼睑及瞳孔中心点)和视线方向,最终输出包含精确关键点坐标与视线方向的双重结果,实现对眼部状态与注视行为的协同建模。

图3 基于多任务的视线估计方法
尽管面部特征中蕴含着全面的视线信息,然而,由于面部区域广阔,眼部信息的损失较为严重。此外,模型难以直接从整个面部中捕捉到与视线最相关的区域,这无疑增加了模型的复杂度。故拟计划通过多尺度输入,即同时将面部图像、左右眼图像进行输入,即可提升眼部区域的分辨率,保留更多细节信息,同时多输入能够降低模型训练难度,具体如图4 所示,通过预处理获取面部区域和左右眼的图像,分别通过网络进行编码,然后将单分支特征进行拼接,预测视线方向。

图4 基于面部和眼部的视线估计方法
2.3 引入时序信息
在实际应用中,单帧图像可能会遇到眼部被光线遮挡等问题,这可能导致视线估计的预测错误或不稳定。为了进一步增强模型的稳定性和提升预测效果,引入时序信息成了一种切实有效的解决途径。该模型由静态(Static)和时序(Temporal)两个主要处理模块组成,如图5 所示。

图5 基于时序信息的视线估计方法
静态模块针对每个时间点t0,t1,……,tn的输入图像,利用CNN 技术精准提取每一帧图像的关键特征。时序模块将提取的图像特征输入到循环神经网络(RNN)中,分析随时间不断变化的视线模式。通过多个RNN 层,模型能够学习到视线方向随时间的动态变化。这种结合空间特征提取和时间序列分析的模型架构,能够有效地估计视线方向(gaze)[7],即使存在头部运动、眼部遮挡等不稳定因素,以及在不同相机焦距和光照变化的情况下也能保持较高的准确性。
2.4 域自适应技术
视线感知任务是一个精细化的预测任务,其结果受到个体差异(如不同的面部特征、眼睛形状等)、环境(如车内装饰、座椅位置等)、光照以及配饰等多种因素的影响。为了进一步增强视线感知模型的泛化能力,确保其在各种座舱场景下均能表现出色,我们采用了基于多维度一致性约束的先进域自适应方法。具体来说,通过构建相同样本不同增强方式、不同样本相近视线方向的样本对。其中,增强样本主要用于对抗环境变化的影响,例如通过模拟不同的光照条件、添加噪声等方式来生成增强样本,使模型能够在各种复杂的环境下都能正常工作;另一个样本则将注视方向与源领域的正向样本进行对齐,促进模型学习一致的注视特征,并去除与视线无关的信息。这样可以有效地减少个体差异和环境因素对模型性能的影响,提高模型的泛化能力。如图6 所示,基于一致性约束的特征增强技术通过构建特定的样本对,实现了模型在不同场景下的自适应调整。

图6 基于一致性约束的特征增强技术
3 应用效果
经过严谨的台架测试,视觉感知系统在各类场景下的表现均符合预期。系统精准识别了驾驶员视线方向,准确显示对应区域,13 项测试全部通过,全面验证了座舱视觉感知系统的精准度与稳定性。测试覆盖驾驶员头部姿态与视线方向的多种组合,具体表现如表2 所示。
表2 注视感知台架实现测试结果

基于奇瑞瑞虎8PRO 车型的实车测试进一步印证了系统的优异性能,具体测试如表3所示,在不分心区域,所有测试项目的召回率均达到100%;在分心区域,平均召回率为98.75%,仅在仰视右车窗这一极具挑战性的项目中,召回率为60%。综上所述,实车测试充分验证了系统的高准确率与稳定性区域感知能力,所有测试项目均圆满达成预期目标。
表3 实车视线检测(分心检测)测试结果

研究围绕基于大模型的汽车座舱视觉感知技术开展了深入探究,针对视线感知过程中存在的一系列挑战,提出了一套完备的技术方案,提升了汽车座舱视觉感知系统的准确性与稳定性,为驾驶员营造更为安全、舒适的驾驶环境。后续研究可进一步对各技术环节加以优化,结合更多实际应用场景与数据,持续完善和改进该技术,推动汽车座舱视觉感知技术的广泛应用与发展。
参考文献:
[1] 李函遥,王 ,郁淑聪.智能座舱人机交互发展趋势[J].时代汽车,2022(23):16-18.
[2] 王飞.汽车智能座舱中人脸活体检测与视线估计算法研究[D].长春:吉林大学,2024.
[3] 刘斌.智能座舱多模态交互技术发展现状及趋势分析[C] //重庆市大数据和人工智能产业协会.人工智能与经济工程发展学术研讨会论文集(一),2025:421-424.
[4] 杨艳艳,李雷孝,林浩.提取驾驶员面部特征的疲劳驾驶检测研究综述[J].计算机科学与探索,2023,17(06):1249-1267.
[5] 程鸣.基于视觉的驾驶员疲劳与分心行为监测方法研究[D].武汉:武汉科技大学,2024.
[6] 程明月.基于深度神经网络的复杂时序数据表征学习方法研究[D].合肥:中国科学技术大学,2023.
[7] Y Zhang, X., Sugano, Y., Fritz, M., &Bulling, A. Appearance-based gaze estimation in the wild[J]. In Proceedings of the IEEE conference on computer vision and pattern recognition ,2015(06):4511-4520.
-

Digi-Key KOL 系列:商务车型的影音娱乐系统应用方案
-

由内到外的智能网联车:车联网现状及发展
-

labview2016
-

直播回放: TI DLP® 技术在汽车上的创新及全新应用
-

回放 : TI mmWave 毫米波雷达在汽车车内的应用
-

Amplifier Protection Series
-
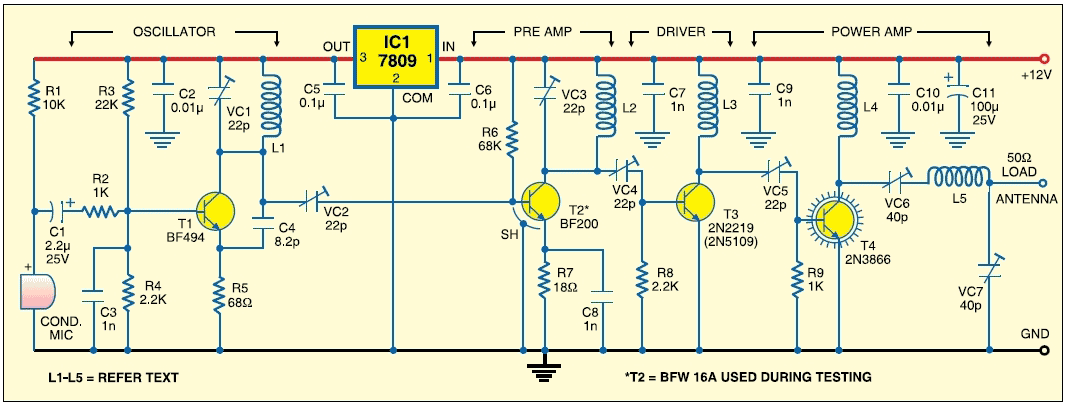
1瓦四级调频发射机
-

500W MOS场效应管电源逆变器,12V转110V/220V
-

12V 转 28V DC-DC 变换器(基于 LM2585)
-
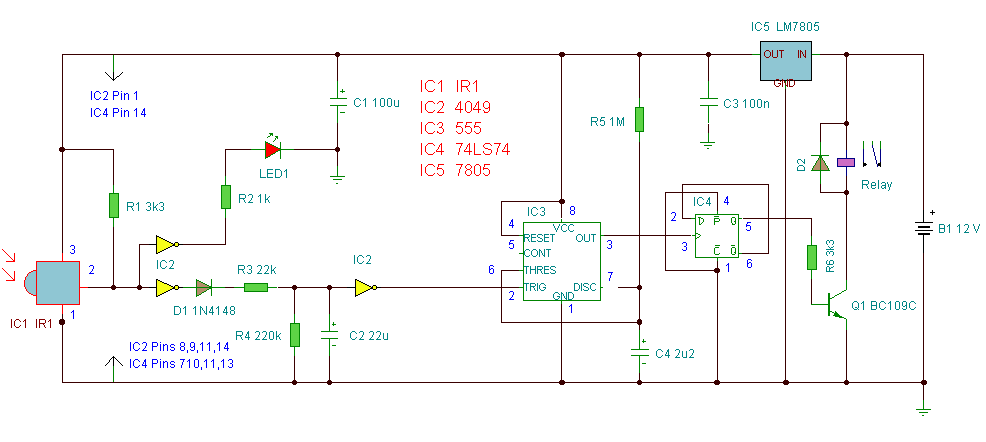
红外开关
-
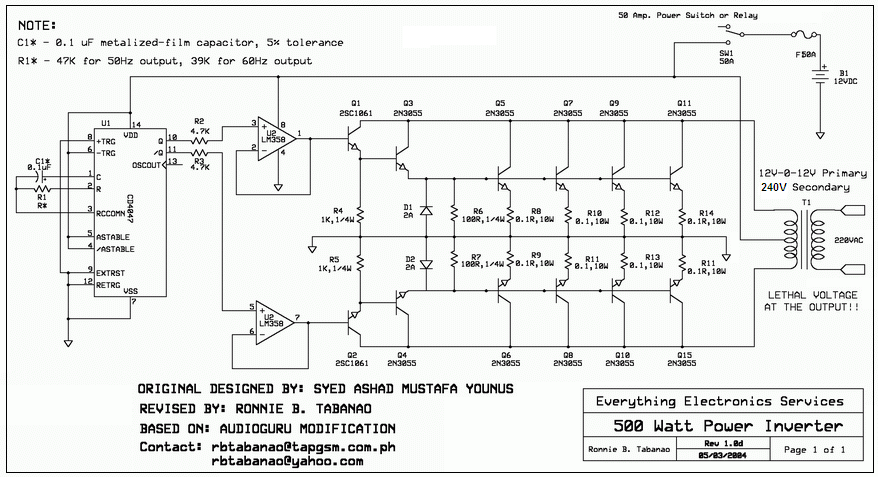
12V转110V/220V 500W逆变器
-
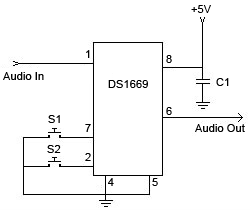
DS1669数字电位器