



SiFive发布第二代智能处理器家族,涵盖物联网到AI
2025-09-17 来源:EEWORLD
SiFive 近日宣布对其产品矩阵进行大规模更新,新产品覆盖从极边缘物联网设备的超低功耗设计,到 AI 数据中心的高性能引擎等广泛领域。第二代 RISC-V 智能处理器 IP 家族包含五款新产品 —— 全新设计的 X160 Gen 2 和 X180 Gen 2,以及升级后的 X280、X390 和 XM 核心。

该系列产品不仅拓展了 SiFive 在极边缘和嵌入式 AI 领域的布局,还通过性能与功能提升,瞄准云端更严苛的推理和训练应用。其架构针对 AI 算法定制,优化了内存子系统,配备可配置缓存和新型内存延迟容忍机制,能在高负载工作流下掩盖延迟并最大化吞吐量。此外,第二代智能家族支持更多数据类型,包括原生 BF16 格式(广泛用于 AI 训练)和向量加密扩展,进一步扩大工作负载覆盖范围。
五款新成员覆盖全场景应用

X160 Gen 2:专为物联网和边缘计算优化,尺寸极小且能效突出;
X180 Gen 2:为边缘推理提供更强算力,同时支持数据中心环境的集成需求;
X280 Gen 2:面向智能家居和可穿戴设备;
X390:针对工业边缘和移动应用;
XM Gen 2:具备大规模向量与矩阵计算能力,适配大语言模型(LLM)等高强度应用。
该家族的核心优势在于支持向量计算的 RISC-V 架构。与标量设计不同,向量核心通过并行处理多数据项降低指令开销和功耗,尤其适用于使用小数据类型的 AI 模型。
全新接口赋能加速器控制

除核心升级外,SiFive 还为第二代智能家族引入新接口:
SSCI(标量协处理器接口):通过 RISC-V 自定义指令驱动加速器,直接访问 CPU 寄存器并支持灵活指令操作码;
VCIX(向量协处理器接口):使用通用向量指令格式,为处理器向量寄存器提供高带宽访问。
这些接口使所有智能核心可作为加速器控制单元(ACU),以低延迟管理定制 AI 加速器。
内存延迟容忍技术与性能突破

SiFive 宣称新产品性能显著提升:在 MLPerf Tiny 基准测试中,X160 Gen 2 在关键词检测、图像分类和异常检测等任务中,性能达到同类小尺寸方案的 2 倍。这类任务对计算资源有限但需 AI 能力的可穿戴设备、智能家居和工业边缘系统至关重要。而 XM Gen 2 算力可达数千 TOPS,适用于数据中心级生成式 AI 工作流。
软件层面,SiFive 的框架集成了 TensorFlow Lite、ONNX Runtime 和 Llama.cpp 等主流 AI 运行时与库,并提供自有编译器扩展和内核库。
市场机遇与挑战
SiFive 引用的研究显示,AI 正加速 RISC-V 的采纳,预计未来几年 RISC-V AI 处理器出货量将快速增长。德勤数据表明,全计算领域的 AI 工作负载增长 20%,边缘工作负载预计增长近 80%。
尽管开放的 RISC-V 架构消除了许可成本并支持定制化,SiFive 仍需与 Arm、Intel 和 NVIDIA 等老牌厂商竞争。其独特策略是将高效标量/向量计算与灵活加速器控制接口结合,减少对专有互联或中间件的依赖,使 IP 兼具成本效益和适应性。
若 SiFive 能证明第二代产品家族在降低 AI 开发难度的同时满足性能与效率目标,将有望在边缘市场巩固地位,并切入数据中心 AI 部署。其成功关键在于执行能力 —— 尤其是与软件框架的兼容,以及 2026 年 Q2 流片后在量产芯片中验证可扩展性。
- SiFive车规级RISC-V IP获IAR最新版嵌入式开发工具全面支持,加速汽车电子创新
- Upbeat开发采用SiFive内核的MCU,集成自研NPU
- SiFive 推出全新 RISC-V IP,融合标量、向量与矩阵运算,加速从边缘物联网到数据中心 AI 应用
- SiFive 推出第二代 RISC-V AI 处理器内核,包含两款全新边缘 IP
- RISC-V之父Krste Asanović:相信RISC-V未来会成为最主流的ISA
- SiFive CEO:RISC-V如何塑造计算的未来
- SiFive 车规级 处理器丨SiFive确认申报2024金辑奖
- SiFive 宣布推出全新高性能 RISC-V 数据中心处理器,适用于高强度的 AI 工作负载
- 对标 Arm Neoverse N2,SiFive 推出数据中心级 RISC-V 内核设计 P870-D
- 瑞萨电子推出全新GaN充电方案, 为广泛的工业及物联网电子设备带来500W强劲功率
- 半年翻三倍!三星2nm良率涨至60%以上:紧追台积电
- 倪光南:半导体行业不再是先进制程包打天下的局面
- 意法半导体与英伟达合作加快物理AI全面普及和市场增长
- 贸泽电子荣获海关AEO高级认证 ——迈向国际贸易合规与供应链安全重要里程碑
- 全国首条 8 英寸硅光芯片量产线在苏州开工建设,预计 2027 年初投产
- 不只是PCB工具:拆解 Altium Develop 背后的平台化雄心
- Agentic AI时代,RISC-V如何突围?玄铁给出了答案
- All in AI再落一子:深度解读安谋科技“玲珑”V560/V760
- 资腾亮相SEMICON China展示CMP超洁净刷轮,助力先进制程良率提升
-

直播回放: 如何使用MPLAB® Mindi™软件进行模拟电路仿真
-

直播回放: 开启 SDV 的未来:集成 TI 的远程控制边缘节点解决方案
-

直播回放: 2026 是德科技XR8新品发布: 一段跨越70年的示波器创新之旅
-

直播回放: 使用RUHMI模型转换器部署BYOM模型并进行MINST模型部署
-

直播回放: 使用Reality AI Tools 基于数据创建微小型AI模型以及进行拉弧检测开发实践
-

直播回放: MPS 赋能人形机器人 - 因为没有运动,机器人只是一尊雕塑
-
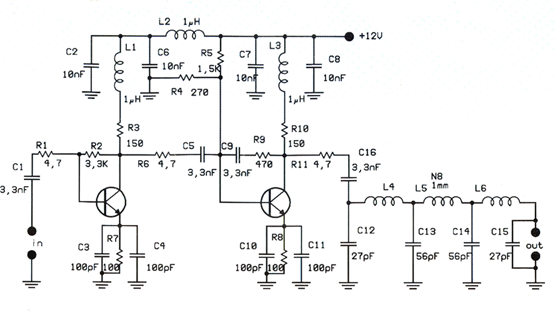
1瓦线性调频增强器
-
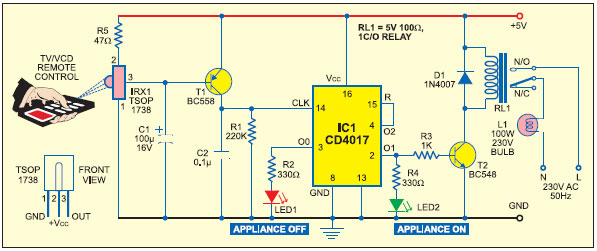
家用电器遥控器
-

12V 转 28V DC-DC 变换器(基于 LM2585)
-
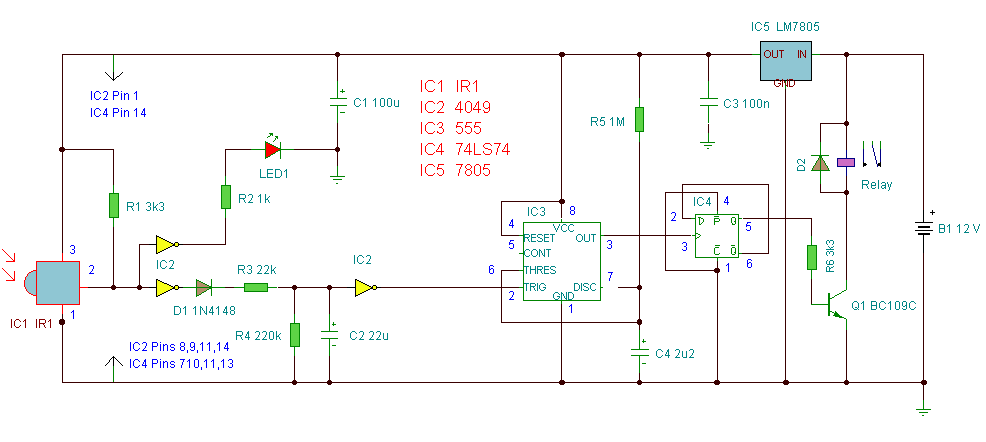
红外开关
-
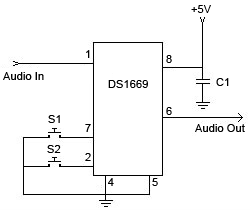
DS1669数字电位器
-
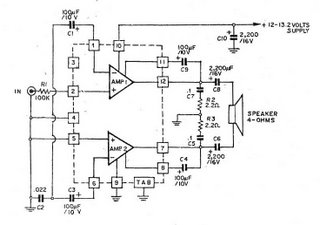
HA1377 桥式放大器 BCL 电容 17W(汽车音频)